
SUMMARY
Microservices Architecture Explained: Design Patterns & Best Practices in 2026
A comprehensive guide to microservices architecture for backend developers, covering essential design patterns, communication strategies, and best practices for building scalable, resilient systems.
Keywords: Microservices, Backend Development, Distributed Systems
TABLE OF CONTENTS
1. Introduction: The Evolution to Microservices
2. Core Design Patterns for Microservices
3. Communication Strategies in Distributed Systems
4. Data Management and Consistency Challenges
5. Achieving Observability in Microservices
6. Solving Common Microservices Problems
7. Practical Application: Building a Microservices System
8. Frequently Asked Questions (FAQ)
INTRODUCTION
The Evolution to Microservices
In the rapidly evolving landscape of software development in 2026, building scalable, resilient, and maintainable applications is more crucial than ever. For many years, the monolithic architecture served as the default choice, where all components of an application were tightly coupled and deployed as a single unit. While simple to develop initially, monoliths often faced significant challenges as applications grew in size and complexity, leading to slower development cycles, difficulties in scaling specific components, and a higher risk of system-wide failures.
This gave rise to the microservices architecture, a paradigm that structures an application as a collection of loosely coupled, independently deployable services. Each service typically focuses on a single business capability, operates in its own process, and communicates with other services through lightweight mechanisms, often using HTTP/REST APIs or asynchronous message queues. This architectural style has become a cornerstone for cloud-native applications and large-scale distributed systems, adopted by tech giants and startups alike.
The benefits are compelling: enhanced agility, improved scalability, greater resilience, and the flexibility to use diverse technologies. Teams can develop, deploy, and scale services independently, accelerating time-to-market. For instance, a major e-commerce platform might have separate microservices for user authentication, product catalog, order processing, and payment gateway, each managed by a dedicated team. However, this power comes with increased operational complexity, necessitating careful design and robust best practices. This guide aims to demystify microservices, exploring essential design patterns and strategies to help backend developers navigate this powerful architecture in 2026.
KEY POINT
Microservices architecture breaks down monolithic applications into smaller, independent services, offering significant advantages in scalability, resilience, and development agility, but introduces new challenges in distributed system management.
CORE CONTENT
Core Design Patterns for Microservices
The first and most critical step in adopting microservices is deciding how to break down your application. Poor decomposition can lead to a distributed monolith, negating the benefits of the architecture. Two primary strategies guide this process:
Service Decomposition Strategies
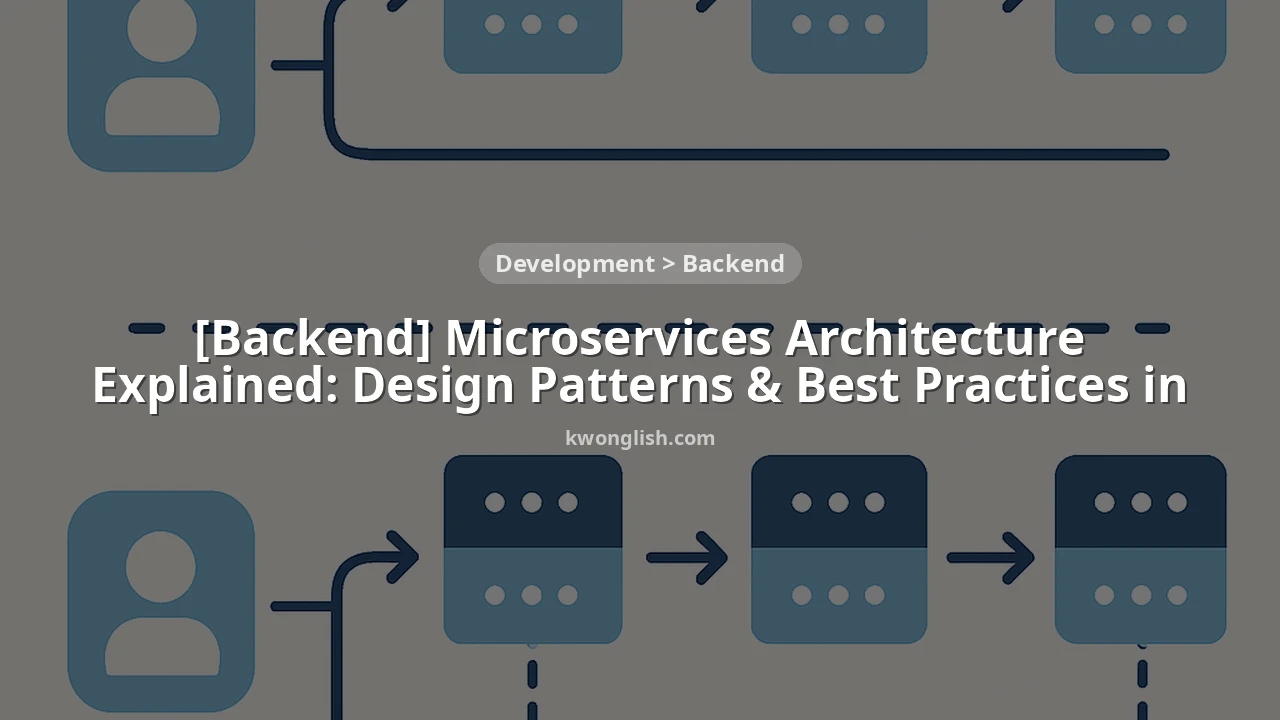
1. Decompose by Business Capability: This approach focuses on identifying core business functions and encapsulating them within separate services. Each service owns a distinct business domain and is responsible for its data and logic. For example, in an e-commerce system, you might have services for:
• User Management Service: Handles user registration, profiles, authentication.
• Product Catalog Service: Manages product listings, inventory, search.
• Order Processing Service: Manages order creation, status updates, fulfillment.
• Payment Service: Integrates with payment gateways, handles transactions.
This method ensures that each service is cohesive and loosely coupled, making it easier for teams to work independently and scale specific functionalities. For instance, during a flash sale, only the Product Catalog and Order Processing services might need significant scaling, not the entire application.
2. Decompose by Bounded Context: Originating from Domain-Driven Design (DDD), this strategy emphasizes defining clear boundaries around different parts of the domain model. A bounded context represents a specific functional area where a particular domain model is consistent. For example, the concept of “Product” might be different in a “Catalog Management” context (with attributes like SKU, description, price, images) versus a “Shipping” context (where it might only need weight, dimensions, and destination). Each bounded context becomes a microservice, ensuring internal consistency and preventing model leakage across services.
KEY POINT
Effective service decomposition is paramount. Decomposing by business capability and bounded context ensures services are cohesive, manageable, and truly independent, preventing the creation of a distributed monolith.
Communication Strategies in Distributed Systems
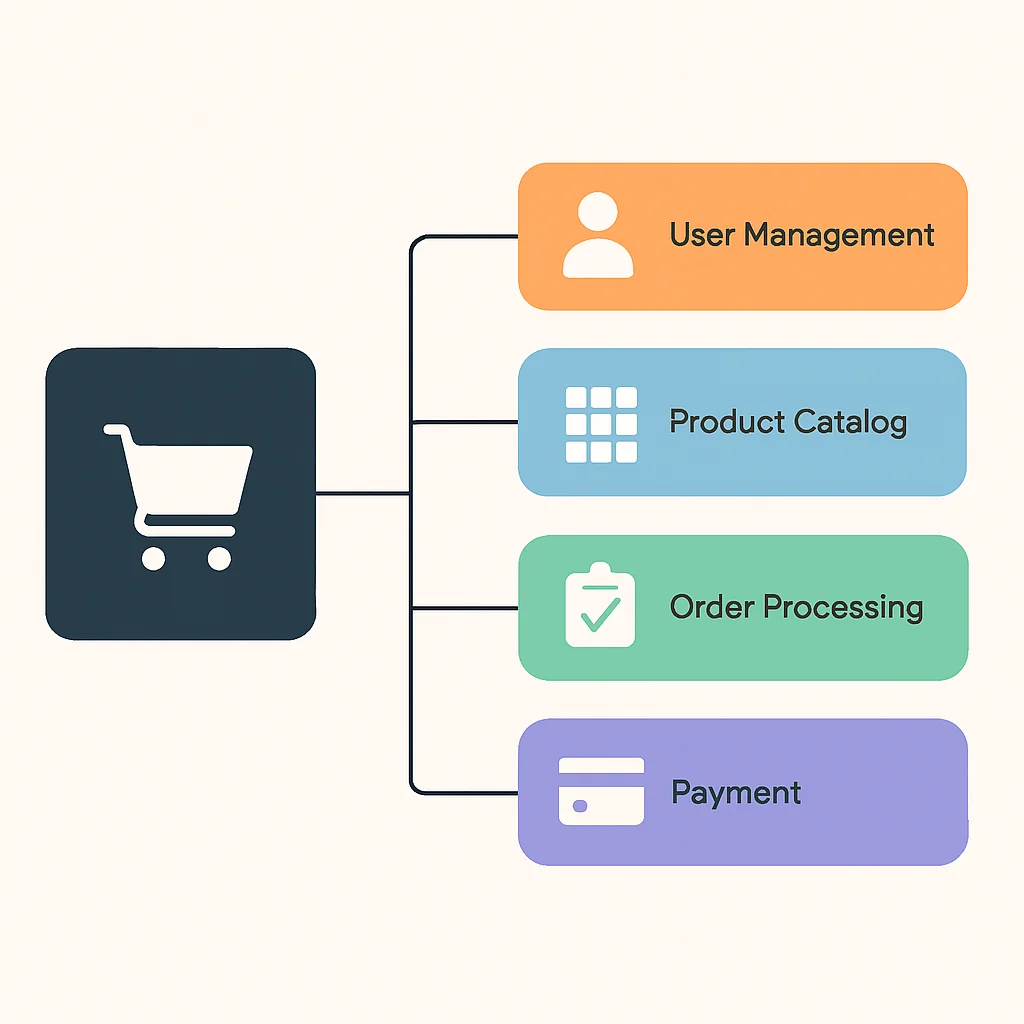
Microservices rely heavily on efficient and robust communication. The choice of communication style significantly impacts system performance, resilience, and complexity. We generally categorize communication into synchronous and asynchronous patterns.
1. Synchronous Communication: This involves a client service making a request and waiting for a response from a server service. Common protocols include:
• REST (Representational State Transfer) over HTTP: The most prevalent choice due to its simplicity, widespread tooling, and stateless nature. Ideal for request-response interactions like fetching user data or submitting an order. However, it introduces tight coupling in terms of availability — if the target service is down, the calling service will fail.
• gRPC (Google Remote Procedure Call): A high-performance, open-source RPC framework. It uses Protocol Buffers for serialization, offers strong typing, and supports streaming. gRPC is often preferred for internal service-to-service communication where performance is critical, and bandwidth efficiency is desired. It typically sees latency improvements of 5-10x over REST in high-throughput scenarios.
2. Asynchronous Communication: This involves services communicating without waiting for an immediate response. It enhances resilience and decouples services by introducing a message broker. Key patterns include:
• Message Queues (e.g., RabbitMQ, Apache ActiveMQ): A service sends a message to a queue, and another service consumes it later. This is excellent for long-running processes, batch processing, or when the sender doesn’t need an immediate response. It provides buffering and retry mechanisms, improving fault tolerance.
• Event Streaming (e.g., Apache Kafka): Services publish events to topics, and other services subscribe to these topics. This pattern is fundamental for event-driven architectures, allowing services to react to changes in the system. Kafka, for instance, can handle millions of messages per second, making it suitable for real-time data pipelines and complex event processing.
The API Gateway Pattern: For external clients (web browsers, mobile apps), direct access to microservices is impractical and insecure. The API Gateway acts as a single entry point, routing requests to the appropriate services, handling authentication/authorization, rate limiting, and transforming requests/responses. This pattern simplifies client-side development and adds a layer of security and resilience. A well-designed API Gateway can reduce client requests from 10-15 direct calls to a single, aggregated call, significantly improving performance for client applications.
CODE EXPLANATION
This is a simplified configuration for an API Gateway using Spring Cloud Gateway, demonstrating how to route requests to different microservices based on the path. It routes requests starting with /users to the user-service and /products to the product-service.
spring:
cloud:
gateway:
routes:
- id: user_service_route
uri: lb://user-service
predicates:
- Path=/users/**
filters:
- RewritePath=/users/(?<segment>.*), /$\{segment}
- id: product_service_route
uri: lb://product-service
predicates:
- Path=/products/**
filters:
- RewritePath=/products/(?<segment>.*), /$\{segment}
This configuration uses a load balancer (lb://) to distribute requests to available instances of user-service and product-service, providing basic service discovery and load balancing.
KEY POINT
Choosing the right communication pattern (synchronous vs. asynchronous) depends on the specific use case. The API Gateway pattern is essential for externalizing microservices, providing a unified and secure entry point.
Data Management and Consistency Challenges
One of the most significant shifts in microservices is how data is managed. Unlike monoliths that typically share a single database, microservices advocate for decentralized data management. This principle is often referred to as “Database per Service.”
Database per Service Pattern: Each microservice owns its data store, which can be a separate database instance, a separate schema within a database, or even a completely different type of database (e.g., a relational database for user data, a NoSQL document database for product catalogs, and a graph database for recommendations). This provides several advantages:
• Autonomy: Services can evolve their schemas independently without impacting other services.
• Technology Freedom: Teams can choose the best database technology for their specific service’s needs.
• Scalability: Databases can be scaled independently, optimizing resource utilization.
However, this pattern introduces the challenge of maintaining data consistency across multiple services, especially for operations that span several services (distributed transactions).
The Saga Pattern for Distributed Transactions: Traditional ACID transactions (Atomicity, Consistency, Isolation, Durability) are not feasible across service boundaries. The Saga pattern provides a way to manage distributed transactions by breaking them down into a sequence of local transactions, each within a single service. If a local transaction fails, the saga executes compensating transactions to undo the preceding successful transactions, ensuring eventual consistency.
There are two main approaches to implement a Saga:
• Choreography: Each service publishes events, and other services react to these events, triggering their own local transactions. This is decentralized and simpler for smaller sagas, but harder to monitor and debug as the number of services grows. For example, an OrderCreated event might be published by the Order Service, picked up by the Payment Service to process payment, which then publishes a PaymentProcessed event, and so on.
• Orchestration: A central orchestrator (a dedicated service) manages the sequence of local transactions and compensates if necessary. This provides better control and visibility but introduces a single point of failure and potential bottleneck. The orchestrator explicitly tells each service what local transaction to execute. For instance, in a complex order process involving 5 services, an orchestrator service would coordinate each step, waiting for confirmation before proceeding.
Choosing between choreography and orchestration depends on the complexity of the distributed transaction. Choreography is often favored for simpler flows, while orchestration provides more control for complex business processes involving 3+ services. In 2026, tools like Cadence or Temporal are gaining traction for building robust saga orchestrators.
KEY POINT
The “Database per Service” pattern promotes autonomy but necessitates strategies like the Saga pattern for maintaining data consistency across distributed transactions.
Achieving Observability in Microservices
In a distributed microservices environment, understanding system behavior and diagnosing issues becomes significantly more complex than in a monolith. This is where observability comes into play, encompassing logging, monitoring, and distributed tracing.
1. Centralized Logging: With dozens or even hundreds of services generating logs, collecting them in a centralized system is crucial. Tools like the ELK stack (Elasticsearch, Logstash, Kibana) or Splunk allow developers to search, analyze, and visualize logs from all services in one place. Each log entry should include correlation IDs (e.g., trace ID, request ID) to link related log messages across different services for a single request. A typical system with 50 microservices can generate terabytes of log data daily, making efficient log aggregation and indexing indispensable.
2. Monitoring: Monitoring provides insights into the health and performance of individual services and the overall system. Key metrics to collect include CPU utilization, memory usage, network I/O, request rates, error rates, and latency. Popular monitoring stacks include Prometheus for metric collection and Grafana for visualization and alerting. Dashboards should be tailored to show critical metrics for each service and aggregated views for the entire system, enabling proactive issue detection. For example, a 10% increase in error rates on the payment service could trigger an alert to the operations team.
3. Distributed Tracing: When a user request spans multiple microservices, it can be challenging to understand the full flow and identify performance bottlenecks. Distributed tracing systems (e.g., Jaeger, Zipkin, OpenTelemetry) track a single request as it propagates through various services. Each operation in a service generates a “span,” and all spans related to a single request are grouped into a “trace.” This allows developers to visualize the entire request path, measure latency at each step, and pinpoint exactly where an issue occurred. For instance, if an API call to fetch user data takes 500ms, tracing can reveal if 400ms was spent in the database service or a downstream authentication service.
KEY POINT
Comprehensive observability (centralized logging, robust monitoring, and distributed tracing) is non-negotiable for effectively managing and troubleshooting microservices in production environments.
PROBLEM SOLVING
Solving Common Microservices Problems
Ensuring Data Consistency in Distributed Transactions
One of the most complex challenges in microservices is maintaining data consistency when a single business operation spans multiple services, each with its own database. Traditional ACID transactions are not possible across service boundaries, leading to potential inconsistencies if one part of the operation fails.
SOLUTION — Implement the Saga Pattern
The Saga pattern is the go-to solution for managing distributed transactions. It breaks down a transaction into a sequence of local transactions, each updating its respective service’s database. If any local transaction fails, compensating transactions are executed to undo the effects of previous successful local transactions, ensuring eventual consistency. For example, consider an order placement requiring updates to Inventory, Payment, and Shipping services:
1. Order Service: Creates order, sets status to PENDING.
2. Inventory Service: Reserves stock. If successful, notifies Payment Service.
3. Payment Service: Processes payment. If successful, notifies Shipping Service.
4. Shipping Service: Schedules shipment. If successful, notifies Order Service.
5. Order Service: Updates order status to CONFIRMED. If any step fails (e.g., payment fails), compensating transactions are triggered: Payment Service refunds, Inventory Service releases stock, Order Service sets status to CANCELLED. This ensures atomicity across services without a two-phase commit.
CODE EXPLANATION
This pseudo-code illustrates a simplified choreography-based saga for an order process. Each service reacts to events published by others, initiating its local transaction. If a failure occurs (e.g., PaymentFailedEvent), compensating actions are triggered.
// Order Service
public void createOrder(Order order) {
order.setStatus(OrderStatus.PENDING);
orderRepository.save(order);
eventPublisher.publish(new OrderCreatedEvent(order.getOrderId(), order.getProductId(), order.getQuantity(), order.getTotalAmount()));
}
// Inventory Service (listener for OrderCreatedEvent)
public void handle(OrderCreatedEvent event) {
if (inventoryService.reserveStock(event.getProductId(), event.getQuantity())) {
eventPublisher.publish(new StockReservedEvent(event.getOrderId()));
} else {
eventPublisher.publish(new StockReservationFailedEvent(event.getOrderId()));
}
}
// Payment Service (listener for StockReservedEvent)
public void handle(StockReservedEvent event) {
if (paymentGateway.processPayment(event.getOrderId(), event.getAmount())) {
eventPublisher.publish(new PaymentProcessedEvent(event.getOrderId()));
} else {
eventPublisher.publish(new PaymentFailedEvent(event.getOrderId()));
}
}
// Order Service (listener for StockReservationFailedEvent or PaymentFailedEvent)
public void handle(StockReservationFailedEvent event) {
Order order = orderRepository.findById(event.getOrderId());
order.setStatus(OrderStatus.CANCELLED);
orderRepository.save(order);
// Potentially publish OrderCancelledEvent
}
Service Discovery
In a microservices architecture, instances of services are dynamically created, scaled, and destroyed. How does one service find and communicate with another without hardcoding IP addresses or ports? This is the problem of service discovery.
Solution: Service discovery mechanisms allow services to register themselves with a central registry and look up other services. There are two main types:
• Client-Side Discovery: The client service is responsible for querying a service registry (e.g., Eureka, Consul, Apache Zookeeper) to get the network locations of available service instances and then load-balancing requests among them. This adds complexity to the client but offers flexibility.
• Server-Side Discovery: The client makes a request to a router, which acts as a load balancer (e.g., AWS Elastic Load Balancer, Kubernetes Service). The router queries the service registry and forwards the request to an available service instance. This abstracts discovery from the client, simplifying client-side logic. Kubernetes, for example, provides built-in service discovery via DNS, allowing services to find each other by name (e.g., http://user-service:8080).
In 2026, container orchestration platforms like Kubernetes have largely standardized server-side discovery, simplifying deployments and operations significantly. For environments outside Kubernetes, tools like HashiCorp Consul remain popular, offering DNS-based service discovery and health checking.
KEY POINT
Service discovery is crucial for dynamic microservices environments, enabling services to locate and communicate with each other without manual configuration. Server-side discovery, often provided by orchestrators like Kubernetes, is a dominant pattern in 2026.
Configuration Management
Microservices often require different configurations for various environments (development, staging, production) and may need dynamic updates without redeployment. Managing configuration files scattered across dozens of services can quickly become a nightmare.
Solution: Centralized configuration management systems provide a single source of truth for all service configurations. These systems allow dynamic updates, version control, and environment-specific overrides. Popular solutions include:
• Spring Cloud Config: Integrates seamlessly with Spring Boot applications, allowing configurations to be stored in a Git repository and fetched by services at startup or runtime.
• HashiCorp Consul/Vault: Consul provides a distributed key-value store for configuration, while Vault securely manages secrets (API keys, database credentials). Both are widely used in production for robust configuration and secret management.
• Kubernetes ConfigMaps and Secrets: For applications deployed on Kubernetes, ConfigMaps can store non-sensitive configuration data, and Secrets manage sensitive information securely. These are injected into pods as environment variables or mounted files.
Centralized configuration ensures consistency, reduces manual errors, and improves security by separating sensitive data from application code. Imagine updating a database connection string for 30 services; with a centralized system, it’s a single change, rather than 30 individual updates and redeployments.
KEY POINT
Centralized configuration management is essential for efficiently handling diverse and dynamic configurations across numerous microservices, improving consistency, security, and operational agility.
PRACTICAL APPLICATION
Building a Microservices System: A Practical Guide
Define Bounded Contexts and Service Boundaries
Start by identifying the core business capabilities of your application. Use Domain-Driven Design principles to define clear bounded contexts. Each context should correspond to a microservice. For an online retail platform, this might involve distinct services for Inventory, Catalog, Orders, Payments, and Customer Accounts. Aim for services that are small enough to be managed by a small team (2-8 developers) and can be deployed independently.
Choose Communication Styles and Implement API Gateway
Decide on communication patterns. For client-to-service communication and critical internal sync calls, REST or gRPC are suitable. For event-driven processes, asynchronous messaging with Kafka or RabbitMQ is preferred. Implement an API Gateway (e.g., Spring Cloud Gateway, Nginx, Kong) to handle external requests, routing, authentication, and rate limiting. This acts as the facade for your microservices.
Implement Database per Service and Distributed Transaction Management
Each service should ideally manage its own data store. Select the appropriate database technology for each service (e.g., PostgreSQL for relational data, MongoDB for flexible schemas). For business transactions spanning multiple services, implement the Saga pattern (choreography or orchestration) to ensure eventual data consistency. This might involve using a dedicated saga orchestrator or relying on event-driven communication.
Set Up Comprehensive Observability
Integrate centralized logging (e.g., ELK stack), monitoring (Prometheus + Grafana), and distributed tracing (e.g., Jaeger with OpenTelemetry) from day one. Ensure all services emit logs with correlation IDs. Define key performance indicators (KPIs) and set up alerts for critical metrics. This visibility is vital for debugging, performance optimization, and maintaining system health.
Deploy with Containerization and Orchestration
Containerize each microservice using Docker to ensure consistent environments. Deploy and manage your containers using an orchestration platform like Kubernetes. Kubernetes provides built-in service discovery, load balancing, scaling, and self-healing capabilities, drastically simplifying the operational burden of microservices. Utilize Kubernetes ConfigMaps and Secrets for centralized configuration and secret management.
CODE EXPLANATION
This is a basic Kubernetes Deployment manifest for a microservice. It defines a deployment named user-service, ensuring 3 replicas of the service are running. It specifies the Docker image to use and the port the container exposes.
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service
labels:
app: user-service
spec:
replicas: 3
selector:
matchLabels:
app: user-service
template:
metadata:
labels:
app: user-service
spec:
containers:
- name: user-service
image: your-repo/user-service:1.0.0 # Replace with your actual image
ports:
- containerPort: 8080
env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: app-config
key: database.host
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: app-secrets
key: database.password
This example also shows how to inject configuration from a Kubernetes ConfigMap (for DB_HOST) and a Secret (for DB_PASSWORD), demonstrating best practices for centralized configuration and secure secret management.
KEY POINT
A successful microservices implementation requires a systematic approach, from careful service decomposition and communication design to robust observability and modern deployment strategies using containerization and orchestration platforms like Kubernetes.

Frequently Asked Questions (FAQ)
Q. What is the primary benefit of microservices over a monolithic architecture?
The primary benefit of microservices is enhanced agility and scalability. Teams can develop, deploy, and scale individual services independently, leading to faster development cycles and more efficient resource utilization compared to a tightly coupled monolith.
Q. How do microservices handle data consistency across different services?
Microservices typically use the Saga pattern for distributed transactions to achieve eventual consistency. This involves breaking down a transaction into a series of local transactions, with compensating actions to undo previous steps if a failure occurs, rather than relying on global ACID transactions.
Q. What are the key components for achieving observability in a microservices system?
Key components for observability include centralized logging (e.g., ELK stack), robust monitoring (e.g., Prometheus and Grafana for metrics), and distributed tracing (e.g., Jaeger or OpenTelemetry) to track requests across multiple services.
Q. Is Kubernetes essential for deploying microservices in 2026?
While not strictly essential, Kubernetes has become the de facto standard for deploying and managing microservices in 2026. It provides critical features like service discovery, load balancing, automated scaling, and self-healing, significantly simplifying the operational complexities of distributed systems.
Thanks for reading!
Microservices architecture, while complex, offers unparalleled benefits in scalability, resilience, and development agility when implemented correctly. By understanding and applying the design patterns and best practices discussed, backend developers can build robust and future-proof systems in 2026 and beyond.
Got questions or insights to share about microservices? Drop a comment below and let’s discuss!