

SUMMARY
The Evolving Landscape of Serverless Computing in 2026
This post provides an in-depth analysis of serverless computing’s impact on modern application development, focusing on its benefits, challenges, and future trajectory by 2026.
Keywords: Serverless, Cloud Computing, Application Development
TABLE OF CONTENTS
1. Introduction: The Rise of Serverless
2. Core Analysis: Serverless vs. Traditional Architectures
3. Key Benefits and Platforms
4. Addressing Serverless Challenges
5. Practical Application: Building with Serverless
6. Frequently Asked Questions
7. Conclusion: The Future of Serverless Computing
1. Introduction: The Rise of Serverless
In 2026, the cloud computing landscape continues to evolve rapidly, with serverless architectures emerging as a dominant paradigm for modern application development. The era of developers spending significant time provisioning, managing, and scaling servers is over. Serverless computing, often associated with Function-as-a-Service (FaaS), abstracts the underlying infrastructure, allowing developers to focus purely on writing code.
This transition marks a significant departure from traditional on-premise deployments and even from earlier cloud models like Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS). The allure of serverless is compelling: pay-per-execution billing, automatic scaling to manage fluctuating demand, and a drastic reduction in operational overhead. These benefits are particularly appealing for startups seeking rapid iteration and established enterprises aiming for cost optimization and enhanced agility.
However, grasping the concept of serverless extends beyond merely knowing its definition. It necessitates a thorough exploration of its operational model, a comparison with other cloud strategies, and a realistic assessment of its benefits and inherent challenges. This report aims to deliver a comprehensive analysis of serverless computing, delving into its technical foundations, practical applications, and the strategic implications for businesses in 2026.
KEY POINT
Serverless computing, exemplified by FaaS, is characterized by automatic infrastructure management, pay-per-execution billing, and inherent scalability, allowing developers to concentrate on code logic.
2. Core Analysis: Serverless vs. Traditional Architectures
To truly appreciate serverless, it is essential to understand how it compares to its predecessors: virtual machines (VMs) and containers. Each architecture has its strengths and weaknesses, making the choice dependent on specific project requirements, team expertise, and business objectives.
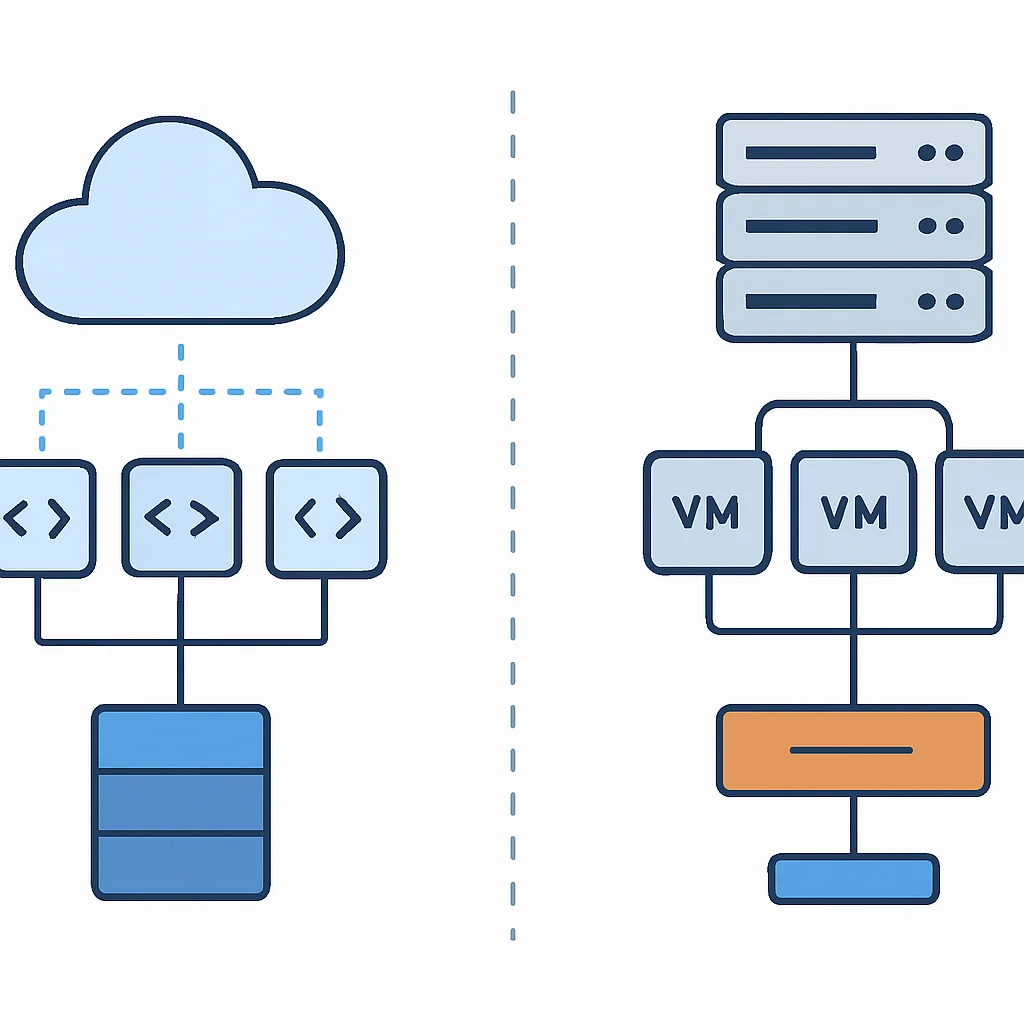
2.1. Virtual Machines (IaaS)
VMs provide the highest level of control, emulating traditional on-premise servers in the cloud. You are responsible for managing the operating system, runtime, and application dependencies. While this offers maximum flexibility, it also incurs significant operational overhead. Tasks such as patching, security updates, scaling, and load balancing fall on the development or operations team.
In terms of cost, VMs are typically billed hourly or by the minute, regardless of whether they are actively processing requests. This “always-on” model can lead to considerable waste during periods of low traffic, with resource utilization often hovering around 10-20% for many applications.
2.2. Containers (PaaS/CaaS)
Containers, popularized by Docker and Kubernetes, provide a lightweight, portable, and consistent environment for applications. They encapsulate an application and its dependencies, ensuring it runs uniformly across different environments. This addresses many of the “it works on my machine” issues common in VM-based deployments.
While containers offer improved resource utilization and faster deployment than VMs, they still require server management. Orchestration platforms like Kubernetes are powerful but complex to set up and maintain. Teams must manage clusters, ensure high availability, and handle scaling policies. Billing is generally based on the underlying compute resources (VMs) that host the containers, often with additional costs for orchestration services.
2.3. Serverless (FaaS)
Serverless takes abstraction to the next level. Developers deploy individual functions, and the cloud provider manages all server management, scaling, and patching. The billing model is revolutionary: you pay only for the compute time your code consumes, typically measured in milliseconds, and the number of invocations. If your function isn’t running, you incur no costs.
This model significantly reduces operational costs and enables developers to focus solely on business logic. Scaling is fully automatic and nearly instantaneous, responding to demand spikes without manual intervention. However, this high level of abstraction introduces its own set of trade-offs, such as potential cold start latencies and the complexities of managing distributed systems.
KEY POINT
Serverless offers unparalleled operational simplicity and cost efficiency through its event-driven, pay-per-execution model, but it requires a different mindset compared to traditional VM or container-based development.
2.4. Comparative Analysis Table
Below is a comparative overview of these architectures as of 2026:
| Feature | Virtual Machines (IaaS) | Containers (PaaS/CaaS) | Serverless (FaaS) |
|---|---|---|---|
| Infrastructure Management | High (OS, runtime, app) | Medium (Container orchestration) | None (Provider managed) |
| Scaling | Manual/Autoscaling groups (slow) | Automated (Kubernetes, faster) | Fully automatic (instantaneous) |
| Billing Model | Hourly/Minutely (always-on) | Resource usage of host VMs | Per execution (ms) + invocations |
| Resource Utilization | Often low (10-20%) | Improved (50-70%) | Near 100% (only when running) |
| Deployment Speed | Days/Weeks | Hours/Days | Minutes |
| Development Focus | Infra + App | Orchestration + App | Purely App Logic |
3. Key Benefits and Platforms
The strategic advantages of adopting serverless are multifaceted, impacting financial efficiency, operational simplicity, and developer agility.
3.1. Core Benefits of Serverless
Operational Advantages
Cost Optimization — Pay only for actual compute time and invocations, leading to significant savings for intermittent workloads. For instance, a small API endpoint might run for a few milliseconds and cost fractions of a cent per request, accumulating to less than $50/month for millions of invocations.
Automatic Scaling — Cloud providers automatically scale functions from zero to thousands of concurrent executions in seconds, eliminating manual scaling efforts and ensuring high availability during peak loads.
Reduced Operational Overhead — No servers to provision, patch, update, or secure. The cloud provider handles all underlying infrastructure management, freeing up engineering teams.
Faster Time to Market — Developers can focus solely on writing business logic, accelerating development cycles and enabling quicker deployment of new features and services.
KEY POINT
Serverless excels in cost efficiency, dynamic scalability, and reduced management burden, making it ideal for event-driven architectures and microservices.
3.2. Leading Serverless Platforms in 2026
The major cloud providers continue to dominate the serverless landscape, each offering robust FaaS platforms and a rich ecosystem of integrated services.
AWS Lambda
The pioneer in FaaS, AWS Lambda remains the market leader. It supports a wide array of languages (Node.js, Python, Java, C#, Go, Ruby, custom runtimes) and integrates seamlessly with over 200 AWS services. Its robust ecosystem includes API Gateway for HTTP endpoints, S3 for storage, DynamoDB for NoSQL databases, and EventBridge for event routing. AWS continues to innovate, offering features like Lambda SnapStart for Java to combat cold starts and provisioned concurrency for critical workloads.
Azure Functions
Microsoft Azure Functions offers a compelling alternative, especially for organizations with existing Microsoft ecosystem investments. It supports similar languages and boasts strong integrations with Azure services like Azure Cosmos DB, Event Hubs, and Logic Apps. Azure Functions provides consumption plans (serverless billing), premium plans (pre-warmed instances), and dedicated plans for more predictable workloads. Its development experience is often praised for its Visual Studio integration.
Google Cloud Functions
Google Cloud Functions (GCF) provides a lightweight and developer-friendly FaaS offering. It integrates tightly with other Google Cloud services like Cloud Pub/Sub, Cloud Storage, and Firebase. GCF is known for its simplicity and fast deployment times, supporting Node.js, Python, Go, Java, .NET, and Ruby. It’s often favored by teams already deeply embedded in the Google Cloud ecosystem or those prioritizing ease of use and rapid prototyping.
4. Addressing Serverless Challenges
Despite its numerous advantages, serverless computing is not without its complexities. Understanding and mitigating these challenges is key to successful adoption.
4.1. Common Serverless Problems and Solutions
PROBLEM 01
Cold Starts
When a serverless function is invoked after a period of inactivity, the cloud provider needs to initialize a new execution environment. This “cold start” can introduce latency, particularly for languages with larger runtimes (e.g., Java, .NET). In 2026, cold starts typically range from 100ms for lightweight Node.js functions to 500-1500ms for Java functions.
SOLUTION
Provisioned Concurrency: Cloud providers offer features (e.g., AWS Lambda Provisioned Concurrency, Azure Functions Premium Plan) to keep a specified number of function instances warm, eliminating cold starts for critical paths.
Optimized Runtimes & Code: Use lightweight runtimes (Node.js, Python) and minimize package sizes. Lazy load dependencies. AWS Lambda SnapStart for Java can significantly reduce cold start times.
Keep-Alive Pings: For less critical functions, scheduled invocations (e.g., every 5-10 minutes) can keep instances warm, though this incurs minimal cost.
PROBLEM 02
Vendor Lock-in
Serverless functions are deeply integrated with their respective cloud provider’s ecosystem (e.g., AWS Lambda with API Gateway, S3, DynamoDB). Migrating a complex serverless application to another cloud provider can be a significant undertaking due to proprietary APIs and service integrations.
SOLUTION
Abstraction Layers: Use frameworks like Serverless Framework or Amplify that provide a degree of abstraction over cloud-specific configurations.
Standardized Interfaces: Design functions to interact with services via generic interfaces (e.g., HTTP APIs, message queues) rather than deeply coupling to proprietary SDKs where possible.
Strategic Multi-Cloud: If multi-cloud is a hard requirement, consider a strategy where core business logic is portable, while less critical components use cloud-specific services. This often means higher operational complexity.
PROBLEM 03
Monitoring and Debugging
Distributed serverless architectures, composed of many small, ephemeral functions, can be challenging to monitor and debug. Tracing requests across multiple functions and services requires specialized tools and practices, as traditional server-based monitoring tools are ineffective.
SOLUTION
Distributed Tracing: Implement distributed tracing (e.g., AWS X-Ray, OpenTelemetry) to visualize the flow of requests across different functions and services.
Centralized Logging: Aggregate logs from all functions into a centralized logging service (e.g., CloudWatch Logs, Stackdriver Logging) for easier searching and analysis.
Specialized APM Tools: Utilize Application Performance Monitoring (APM) tools designed for serverless, such as Datadog, Lumigo, or Thundra, which provide deeper insights into function performance and errors.
KEY POINT
Mitigating serverless challenges like cold starts, vendor lock-in, and complex observability requires strategic architectural choices, tooling, and development practices focused on distributed systems.
5. Practical Application: Building with Serverless
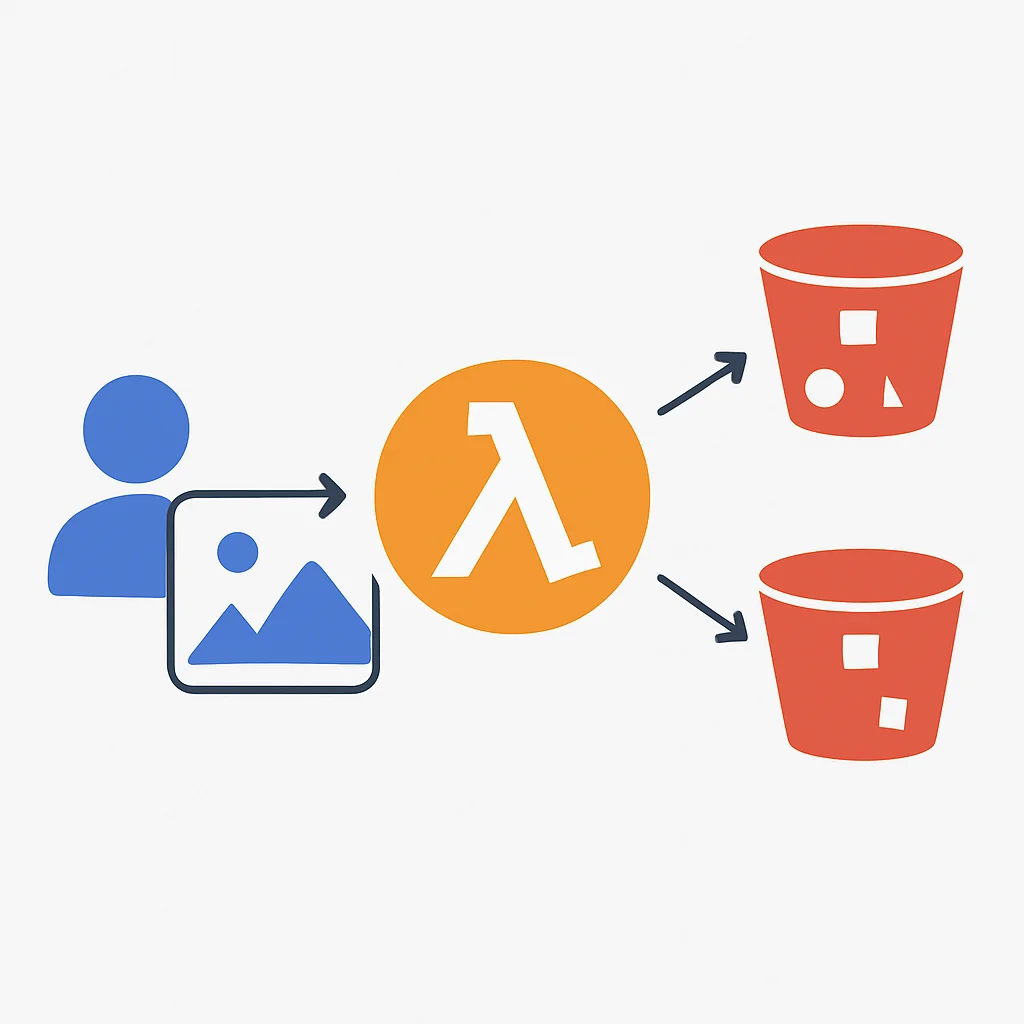
To illustrate the practical aspects of serverless development, let’s consider a common use case: creating a simple image processing service using AWS Lambda and S3. This service will automatically resize uploaded images.
5.1. Use Case: Automated Image Resizing
Imagine you have an application where users upload profile pictures. Instead of manually resizing them or having a dedicated server for this, a serverless function can be triggered every time a new image is uploaded to an S3 bucket. The function will resize the image and save it to another S3 bucket.
Step 1
Set up S3 Buckets
Create two S3 buckets: one for original images (e.g., my-original-images-2026) and another for resized images (e.g., my-resized-images-2026).
Step 2
Create an AWS Lambda Function
Write a Python function that uses the boto3 library to interact with S3 and Pillow (PIL) for image resizing. This function will be triggered by S3 object creation events.
Step 3
Configure S3 Trigger
Set up the my-original-images-2026 bucket to send an s3:ObjectCreated:* event to your Lambda function whenever a new object is put into the bucket.
5.2. Lambda Function Code Example (Python)
CODE EXPLANATION
This Python code defines an AWS Lambda function that processes S3 object creation events. It downloads the original image, resizes it to a specified width (e.g., 200 pixels), converts it to JPEG format, and uploads the resized image to a different S3 bucket. Error handling is included for robustness.
import os
import boto3
from PIL import Image
import io
s3_client = boto3.client('s3')
def lambda_handler(event, context):
for record in event['Records']:
bucket_name = record['s3']['bucket']['name']
key = record['s3']['object']['key']
# Define the target bucket and desired width
target_bucket_name = os.environ.get('TARGET_BUCKET_NAME', 'my-resized-images-2026')
desired_width = int(os.environ.get('DESIRED_WIDTH', '200')) # Default to 200px
try:
# 1. Download the image from the source bucket
response = s3_client.get_object(Bucket=bucket_name, Key=key)
image_content = response['Body'].read()
# 2. Resize the image using Pillow
img = Image.open(io.BytesIO(image_content))
# Calculate new height to maintain aspect ratio
width_percent = (desired_width / float(img.size[0]))
new_height = int((float(img.size[1]) * float(width_percent)))
resized_img = img.resize((desired_width, new_height))
# Convert to JPEG if not already (or if desired for consistency)
if resized_img.mode in ("RGBA", "P"):
resized_img = resized_img.convert("RGB")
# Save the resized image to a buffer
buffer = io.BytesIO()
resized_img.save(buffer, format="JPEG")
buffer.seek(0)
# 3. Upload the resized image to the target bucket
resized_key = f"resized-{key.split('/')[-1].replace('.', '_')}.jpeg" # Ensure JPEG extension
s3_client.put_object(
Bucket=target_bucket_name,
Key=resized_key,
Body=buffer,
ContentType='image/jpeg'
)
print(f"Successfully resized {key} and uploaded to {target_bucket_name}/{resized_key}")
except Exception as e:
print(f"Error processing object {key} from bucket {bucket_name}: {e}")
raise e
return {
'statusCode': 200,
'body': 'Images processed successfully'
}
KEY POINT
This practical example demonstrates how serverless functions can be triggered by events (S3 uploads) to perform automated tasks, showcasing their efficiency for asynchronous, event-driven workloads.
Frequently Asked Questions
Q. What is the main difference between serverless and containers?
The main difference lies in infrastructure management. With containers, you still manage the underlying servers or Kubernetes clusters, whereas serverless abstracts away all server management, allowing you to focus solely on code logic and paying only for execution time.
Q. How does serverless computing save costs?
Serverless saves costs primarily through its pay-per-execution billing model. You are charged only for the actual compute time your code runs, typically in milliseconds, and the number of invocations, eliminating costs associated with idle servers.
Q. What is a “cold start” in serverless, and how is it addressed?
A cold start occurs when a serverless function is invoked after a period of inactivity, requiring the cloud provider to initialize a new execution environment, which can introduce latency. This is addressed using techniques like provisioned concurrency, optimized runtimes, and keeping functions “warm” with periodic pings.
Q. Is serverless suitable for all types of applications?
While highly versatile, serverless is best suited for event-driven, intermittent, or microservices-based workloads. Applications requiring long-running processes, extremely low latency (where cold starts are unacceptable without mitigation), or very high CPU/memory for extended periods might find traditional architectures more appropriate.
7. Conclusion: The Future of Serverless Computing
Serverless computing has firmly established itself as a cornerstone of modern cloud architecture in 2026. Its transformative impact on operational costs, scalability, and developer productivity is undeniable. While challenges like cold starts, vendor lock-in, and observability require careful consideration, ongoing innovations from cloud providers and the growing maturity of serverless tooling continue to mitigate these concerns.
Looking ahead, we can expect several trends to shape the serverless landscape:
✓ Expanded Workloads: Serverless will move beyond simple APIs and event processing to encompass more complex, stateful applications, potentially leveraging new patterns like serverless workflows and orchestration services.
✓ Edge Computing Integration: Tighter integration with edge computing will enable serverless functions to run closer to end-users, reducing latency and enhancing performance for global applications.
✓ Enhanced Observability: Native and third-party monitoring tools will become even more sophisticated, offering deeper insights and simplified debugging for distributed serverless systems.
✓ Hybrid and Multi-Cloud Serverless: While vendor lock-in remains a concern, efforts toward open standards and more portable serverless runtimes (e.g., WebAssembly) could foster a more flexible, hybrid serverless environment.
For organizations navigating the complexities of digital transformation, serverless computing offers a powerful pathway to agility, efficiency, and innovation. By understanding its nuances and adopting best practices, businesses can fully harness the potential of this dynamic technology to build resilient, scalable, and cost-effective applications for the future.
Thanks for reading
We hope this analysis provided valuable insights into the world of serverless computing. Its continuous evolution promises exciting developments for developers and businesses alike.
Got questions or your own serverless experiences to share? Drop a comment below or connect with Kwonglish on social media!