

SUMMARY
Vector Databases Explained: A Developer’s Guide to Pinecone, Weaviate & Milvus in 2026
Dive into the world of vector databases, essential for modern AI applications like RAG and semantic search.
Keywords: Vector Database, Pinecone, Weaviate, Milvus
TABLE OF CONTENTS
1. The Rise of Semantic Search: Why Vector Databases Matter in 2026
2. Understanding Vector Embeddings and Similarity Search
3. Vector Databases in Action: Powering RAG Architecture
4. Deep Dive: Pinecone, Weaviate, and Milvus Comparison
5. Overcoming Challenges in Vector Database Implementation
6. Practical Guide: Building a Simple Semantic Search with Vector Embeddings
7. Real-World Use Cases of Vector Databases
8. Frequently Asked Questions (FAQ)
9. Conclusion: The Future of AI is Vectorized
BACKGROUND
1. The Rise of Semantic Search: Why Vector Databases Matter in 2026
In the rapidly evolving landscape of Artificial Intelligence, the year 2026 marks a significant shift in how we interact with data. Gone are the days when keyword matching alone sufficed for retrieving information. Today, users and AI models alike demand understanding, context, and meaning – a capability powered by what we call semantic search. This paradigm shift is largely enabled by a specialized class of data stores: vector databases.
Traditional databases, whether relational or NoSQL, excel at structured queries, exact matches, and filtering based on predefined attributes. However, they falter when faced with nuanced queries like “find documents similar in meaning to this paragraph” or “recommend products that evoke a similar feeling to this image.” This is where vector databases step in, offering a robust solution for storing, indexing, and querying high-dimensional vectors, which are numerical representations of complex data like text, images, audio, and even user behavior.
The explosion of large language models (LLMs) and generative AI has amplified the need for efficient vector management. Consider applications like Retrieval-Augmented Generation (RAG), where an LLM needs to fetch relevant, up-to-date information from a vast corpus before generating a response. Without a fast and accurate way to find semantically similar data, these systems would be significantly less effective, often leading to hallucinations or irrelevant outputs. Vector databases are the backbone of such intelligent systems, allowing developers to build sophisticated AI applications that truly understand and respond to user intent.
Vector databases are crucial for modern AI applications in 2026, enabling semantic search and contextual understanding by efficiently managing high-dimensional data representations (vectors).
The market for vector databases is experiencing rapid growth, with projections indicating a compound annual growth rate (CAGR) exceeding 25% through 2030, driven by the increasing adoption of AI across various industries. Companies are investing heavily in solutions that can handle billions of vectors with millisecond latency, making this a critical area for developers to master.
CORE CONTENT
2. Understanding Vector Embeddings and Similarity Search
Before diving into the specifics of vector databases, it’s essential to grasp the core concepts they operate on: vector embeddings and similarity search.
What are Vector Embeddings?
A vector embedding is a numerical representation of an object, such as a word, sentence, image, or even an entire document. These representations are typically dense vectors in a high-dimensional space, meaning they consist of hundreds or even thousands of floating-point numbers. The magic of embeddings lies in their ability to capture semantic meaning: objects that are semantically similar are mapped to vectors that are numerically close to each other in this high-dimensional space.
For instance, in the context of natural language processing (NLP), words like “king” and “queen” would have embeddings that are closer to each other than “king” and “apple.” This proximity is not arbitrary; it’s learned by sophisticated machine learning models (like BERT, Word2Vec, or more recently, models from OpenAI, Cohere, or Hugging Face) that process vast amounts of data to understand relationships and contexts.
How Vector Similarity Search Works
Once data is transformed into vector embeddings, the next step is to find items that are “similar” to a given query. This is achieved through vector similarity search. The core idea is to measure the distance or angle between vectors in the high-dimensional space. Common similarity metrics include:
- Cosine Similarity: Measures the cosine of the angle between two vectors. A value of 1 indicates identical direction (perfect similarity), 0 indicates orthogonality (no similarity), and -1 indicates opposite direction (perfect dissimilarity). It’s widely used because it’s sensitive to direction rather than magnitude, making it robust to differences in document length.
- Euclidean Distance: The straight-line distance between two points in Euclidean space. Smaller distances indicate higher similarity. While intuitive, it can be less effective in very high-dimensional spaces compared to cosine similarity for semantic tasks.
- Dot Product: Similar to cosine similarity but also considers vector magnitude. Useful when the magnitude of the vector also carries meaning (e.g., importance or frequency).
Performing an exact similarity search across millions or billions of vectors is computationally expensive (O(N) complexity). To overcome this, vector databases employ Approximate Nearest Neighbor (ANN) algorithms. These algorithms sacrifice a small amount of accuracy for significant speed improvements, allowing searches to return results in milliseconds. Popular ANN algorithms include Hierarchical Navigable Small Worlds (HNSW), Inverted File Index (IVF), and Product Quantization (PQ).
Vector embeddings transform complex data into numerical representations where semantic similarity translates to numerical proximity. Vector databases use ANN algorithms to efficiently find these similar vectors, enabling fast semantic search.
CORE CONTENT
3. Vector Databases in Action: Powering RAG Architecture
One of the most impactful applications of vector databases in 2026 is within the Retrieval-Augmented Generation (RAG) architecture. RAG addresses a critical limitation of Large Language Models (LLMs): their knowledge is static, limited to their training data, and prone to “hallucinations” or generating factually incorrect information.
Understanding Retrieval-Augmented Generation (RAG)
RAG enhances LLMs by providing them with access to external, up-to-date, and domain-specific knowledge bases. The process typically involves these steps:
- Indexing: Your proprietary or external data (documents, articles, web pages, etc.) is chunked into smaller, manageable pieces. Each chunk is then converted into a vector embedding using an embedding model. These embeddings, along with their original text content and any metadata, are stored in a vector database.
- Retrieval: When a user submits a query, it’s also converted into a vector embedding. This query vector is then used to perform a similarity search against the vector database. The database quickly returns the top ‘k’ most semantically similar data chunks.
- Augmentation & Generation: The retrieved chunks of information are then provided to the LLM along with the original user query as part of the prompt. The LLM uses this augmented context to generate a more accurate, relevant, and grounded response, significantly reducing the risk of hallucinations and improving factual consistency.
This architecture is particularly powerful for enterprise solutions, customer support chatbots, and knowledge management systems where LLMs need to leverage specific, frequently updated information that wasn’t part of their original training data. For example, a customer service bot can use RAG to answer questions based on the latest product manuals or internal knowledge base articles, providing precise and current information.
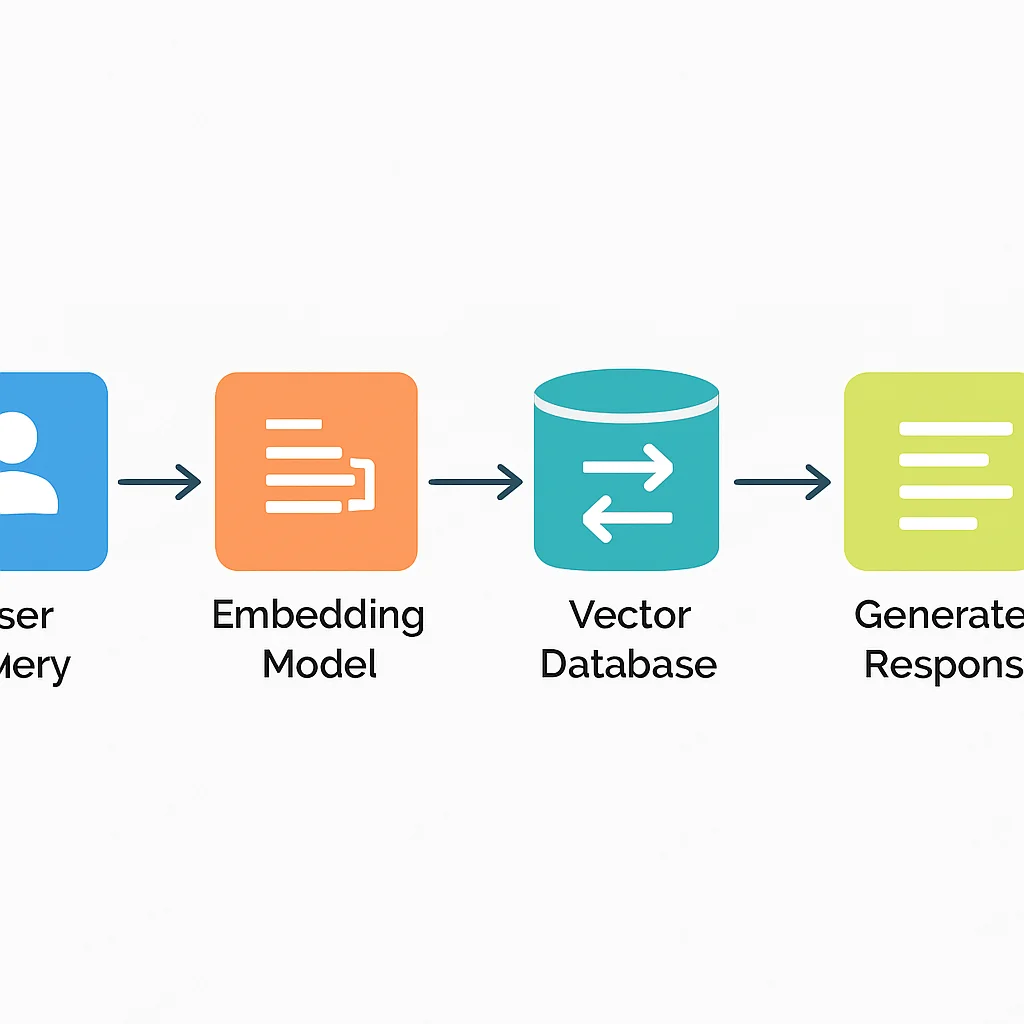
RAG architecture leverages vector databases to provide LLMs with external, up-to-date context, significantly improving the accuracy and relevance of generated responses by grounding them in factual information.
CORE CONTENT
4. Deep Dive: Pinecone, Weaviate, and Milvus Comparison
As of 2026, several robust vector database solutions are available, each with its strengths and target use cases. We’ll compare three leading players: Pinecone, Weaviate, and Milvus.
Pinecone: The Managed Service Powerhouse
Pinecone Overview
Deployment — Fully managed cloud service (SaaS), eliminating operational overhead.
Scalability — Designed for massive scale, handling billions of vectors with high throughput and low latency.
Hybrid Search — Supports both vector similarity search and metadata filtering for precise results.
Ease of Use — Simple API and SDKs for quick integration and development.
Pinecone has established itself as a leading fully managed vector database service. Its primary appeal lies in its simplicity and scalability. Developers can get started almost instantly without worrying about infrastructure provisioning, scaling, or maintenance. Pinecone automatically handles partitioning, indexing, and query routing, making it a favorite for startups and enterprises alike who want to focus purely on building AI applications.
Pinecone supports various Approximate Nearest Neighbor (ANN) indexes, including optimized versions of HNSW, to provide fast and accurate similarity search. It also offers powerful metadata filtering, allowing users to combine semantic search with traditional filtering, for example, “find documents similar to X, but only those published after 2025.” Pricing is typically based on the number of vectors stored and query throughput, with a free tier available for experimentation.
Weaviate: The Graph-Native & Semantic Search Engine
Weaviate Overview
Deployment — Self-hosted (Docker, Kubernetes) or managed cloud service (Weaviate Cloud).
Graph-Native — Stores data as objects with properties, allowing for rich semantic relationships.
Module System — Extensible with modules for different embedding models (e.g., OpenAI, Cohere, Hugging Face), RAG, and more.
GraphQL API — Intuitive API for querying and managing data, including complex graph traversals.
Weaviate stands out with its graph-native approach and robust module system. It can be deployed both self-hosted (on Docker or Kubernetes) and as a managed service, offering flexibility. Weaviate treats data as “objects” with properties and connections, enabling not just vector search but also semantic graph traversals. This makes it powerful for knowledge graphs and applications requiring rich relationships between data points.
Its module system allows users to easily integrate various embedding models, including open-source and proprietary ones, directly into the database. This means Weaviate can automatically vectorize data upon ingestion. The GraphQL API provides a powerful and flexible way to query both vector and scalar data, making complex semantic searches and data explorations straightforward. Weaviate is open-source under a BSD-3 license, appealing to developers who prefer more control and transparency.
Milvus: The Open-Source Vector Search Engine
Milvus Overview
Deployment — Primarily self-hosted (Docker, Kubernetes), with managed options (Zilliz Cloud).
Open-Source — Apache 2.0 licensed, offering full control and community support.
Scalability & Performance — Built for large-scale production environments, distributed architecture.
Flexibility — Supports various ANN algorithms (HNSW, IVF_FLAT, ANNOY) and data types.
Milvus is the veteran among open-source vector databases, offering a highly scalable and performant solution. It’s designed for massive-scale vector search, capable of handling billions of vectors and supporting various ANN indexes. Milvus’s distributed architecture ensures high availability and fault tolerance, making it suitable for critical production deployments.
As an open-source project (Apache 2.0 licensed), Milvus provides developers with complete control over their data and infrastructure. While it requires more operational expertise to set up and manage compared to a fully managed service, it offers unparalleled customization and cost efficiency for those with the resources. Zilliz, the company behind Milvus, also offers a managed cloud service (Zilliz Cloud) for those who prefer a hands-off approach. Milvus is widely used in applications like recommendation systems, image recognition, and intelligent chatbots.
Comparative Analysis Table (2026)
Choosing between Pinecone, Weaviate, and Milvus in 2026 depends on your deployment preference (managed vs. self-hosted), data model complexity (simple vectors vs. graph objects), and the specific features required for your AI application.
PROBLEM SOLVING
5. Overcoming Challenges in Vector Database Implementation
While vector databases offer immense power for AI applications, their implementation comes with its own set of challenges. Understanding these and knowing how to mitigate them is crucial for a successful project in 2026.
Challenge 1: Scalability and Performance at Extreme Volumes
PROBLEM 01
Managing billions of vectors while maintaining sub-100ms query latency.
As data volumes grow, especially in real-time AI systems, ensuring the vector database can scale horizontally and deliver consistent low-latency responses becomes a major hurdle. This impacts user experience and the responsiveness of AI models.
SOLUTION — Choose a distributed architecture and optimize indexing parameters.
For massive scale, opt for vector databases with inherently distributed architectures (like Milvus or managed Pinecone/Weaviate). Carefully select and tune ANN algorithms (e.g., HNSW for balanced accuracy/speed, IVF for high recall). Monitor and adjust parameters like M (number of neighbors for HNSW graph construction) and efConstruction (search scope during graph construction) to balance search accuracy with query speed. Leverage cloud-managed services to offload operational burdens and benefit from their optimized scaling capabilities.
Challenge 2: Data Freshness and Consistency
PROBLEM 02
Keeping vector indexes up-to-date with frequently changing source data, especially in real-time RAG systems.
For applications like real-time news feeds or dynamic product catalogs, the underlying data changes constantly. Re-indexing the entire dataset for every change is impractical. Ensuring the vector database reflects the latest information without excessive resource consumption is a significant challenge.
SOLUTION — Implement incremental indexing and soft deletes.
Most modern vector databases support incremental indexing, allowing you to add, update, or delete individual vectors or batches of vectors without rebuilding the entire index. For updates, it’s often more efficient to perform a “soft delete” (marking a vector as deleted but not immediately removing it) and then insert the new version. Periodically, a garbage collection process can physically remove soft-deleted vectors. For high-frequency updates, consider a streaming data pipeline (e.g., Kafka) to push changes to the vector database in near real-time.
Challenge 3: Cost Optimization
PROBLEM 03
Managing the operational costs associated with storing and querying large vector indexes, especially with high-dimensional vectors.
Vector databases can be resource-intensive, requiring significant memory and CPU for indexing and querying. Cloud-managed services often have usage-based pricing, which can quickly escalate with billions of vectors and high query loads. Self-hosting requires managing infrastructure costs.
SOLUTION — Optimize vector dimensionality and leverage quantization techniques.
Reducing the dimensionality of your vectors (e.g., from 1536 to 768 dimensions) using techniques like PCA or by choosing more efficient embedding models can significantly reduce storage and computational requirements with minimal impact on accuracy. Additionally, many vector databases and ANN algorithms support quantization techniques (e.g., Product Quantization, Binary Quantization) which compress vectors, reducing memory footprint and improving query speed, albeit with a slight trade-off in recall. Regularly review and optimize your embedding generation process.
Effective vector database implementation in 2026 requires strategic planning for scalability, data freshness through incremental updates, and cost optimization via dimensionality reduction and quantization.
PRACTICAL APPLICATION
6. Practical Guide: Building a Simple Semantic Search with Vector Embeddings
Let’s walk through a simplified example of how you might build a semantic search system using Python, focusing on the core concepts of embedding generation and similarity search. For this example, we’ll use a hypothetical scenario and numpy for vector operations, abstracting away the specifics of a particular vector database, though the principles apply directly.
Step 1: Prepare Your Data and Generate Embeddings
1
Define Documents and Mock Embedding Function
We start with a set of documents (sentences in this case) and a placeholder function for generating embeddings. In a real application, this would involve an actual embedding model (e.g., sentence-transformers, OpenAI’s text-embedding-ada-002).
This Python code defines sample documents and a mock get_embedding function. In a production scenario, you would replace this mock with a call to an actual embedding model API or library.
import numpy as np
# Sample documents
documents = [
"The quick brown fox jumps over the lazy dog.",
"A dog is a man's best friend.",
"Cats are known for their independence.",
"Artificial intelligence is transforming industries.",
"Machine learning models require vast amounts of data.",
"Quantum computing is a complex field.",
"The sun rises in the east.",
"Space exploration continues to fascinate humanity."
]
# Mock embedding function - In a real scenario, this would call an actual ML model
def get_embedding(text: str) -> np.ndarray:
"""
Generates a mock vector embedding for a given text.
In a real application, this would use a pre-trained embedding model.
"""
# For demonstration, we'll create a simple hash-based vector
# In reality, embeddings are dense, high-dimensional, and semantically rich.
np.random.seed(hash(text) % (2**32 - 1)) # Seed for consistent mock embeddings
return np.random.rand(128) # 128-dimensional random vector
# Generate embeddings for all documents
document_embeddings = [get_embedding(doc) for doc in documents]
print(f"Generated {len(document_embeddings)} embeddings, each with dimension {document_embeddings[0].shape[0]}.")
Step 2: Implement Similarity Search
2
Calculate Cosine Similarity
We’ll use cosine similarity to measure how “close” our query embedding is to each document embedding. A higher cosine similarity score (closer to 1) means more semantic similarity.
This function calculates the cosine similarity between a query vector and a list of document vectors. It then sorts the documents by similarity to find the most relevant ones.
def cosine_similarity(vec1: np.ndarray, vec2: np.ndarray) -> float:
"""Calculates the cosine similarity between two vectors."""
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
if norm_vec1 == 0 or norm_vec2 == 0:
return 0.0 # Handle zero vectors
return dot_product / (norm_vec1 * norm_vec2)
def semantic_search(query: str, top_k: int = 3):
"""
Performs semantic search on the pre-indexed documents.
In a real vector database, this would be a single API call.
"""
query_embedding = get_embedding(query)
similarities = []
for i, doc_emb in enumerate(document_embeddings):
sim = cosine_similarity(query_embedding, doc_emb)
similarities.append((sim, documents[i]))
# Sort by similarity in descending order
similarities.sort(key=lambda x: x[0], reverse=True)
return similarities[:top_k]
# Example query
query_text = "AI and computer science advancements"
results = semantic_search(query_text)
print(f"\nQuery: '{query_text}'")
print("Top 3 semantically similar documents:")
for sim, doc in results:
print(f"- Similarity: {sim:.4f}, Document: '{doc}'")
This simplified example demonstrates the core logic of semantic search: convert query to embedding, calculate similarity with document embeddings, and retrieve top results. Vector databases automate and optimize these steps at scale.
While this example uses numpy for simplicity, a real-world vector database handles the embedding storage, indexing with ANN algorithms, and optimized similarity search behind a simple API call. The semantic_search function above would be replaced by a single call to pinecone_client.query(), weaviate_client.query.get(), or milvus_client.search(), abstracting away the complex vector operations.
USE CASES
7. Real-World Use Cases of Vector Databases
The versatility of vector databases makes them indispensable across a wide array of industries and applications in 2026. Here are some prominent real-world use cases:
Enhanced Search and Discovery
Semantic Search for E-commerce
Users can search for products using natural language queries like “comfortable shoes for long walks” instead of exact keywords, leading to more relevant results and improved conversion rates. Vector databases power this by matching the query’s semantic meaning to product descriptions, reviews, and images.
Knowledge Base Q&A Systems
Companies use vector databases to power internal knowledge management and customer support. Employees or customers can ask questions in plain English and receive precise answers extracted from large, unstructured document repositories, significantly reducing response times and improving accuracy.
Recommendation Systems
Personalized Content Recommendations
Streaming services, social media platforms, and news aggregators use vector databases to recommend content (movies, articles, music) that is semantically similar to a user’s past interactions or interests. User profiles and content items are embedded as vectors, and similarity search identifies relevant recommendations in real-time.
Product Recommendations in Retail
Beyond semantic search, vector databases enable “similar item” recommendations for retailers. If a customer views a specific shirt, the system can quickly find other shirts that are stylistically and semantically similar, boosting cross-selling opportunities.
Anomaly Detection and Security
Fraud Detection in Financial Services
Transaction patterns, user behavior, and network activities can be embedded as vectors. Vector databases can then quickly identify transactions or behaviors that are significantly dissimilar from established normal patterns, flagging potential fraud or security breaches in milliseconds.
Network Intrusion Detection
By converting network traffic logs or system calls into vectors, security systems can leverage vector databases to detect unusual patterns that might indicate a cyberattack, identifying zero-day exploits that signature-based systems would miss.
Vector databases are versatile tools, enabling advanced capabilities like semantic search, personalized recommendations, and real-time anomaly detection across diverse sectors, making them a cornerstone of modern AI applications.
Frequently Asked Questions (FAQ)
Q. What is the main difference between a vector database and a traditional database?
A. Traditional databases store structured data and excel at exact matches and predefined queries. Vector databases, however, specialize in storing high-dimensional numerical representations (vectors) of unstructured data, enabling semantic search and finding items based on conceptual similarity rather than exact values.
Q. Why are vector databases important for AI applications in 2026?
A. In 2026, vector databases are crucial because they power advanced AI capabilities like semantic search, content recommendations, and Retrieval-Augmented Generation (RAG) for Large Language Models. They allow AI systems to understand context and meaning, leading to more accurate and relevant interactions.
Q. Should I choose a managed vector database like Pinecone or an open-source one like Milvus?
A. The choice depends on your needs. Managed services like Pinecone offer ease of use, zero operational overhead, and instant scalability, ideal for rapid development. Open-source options like Milvus provide greater control, customization, and potentially lower costs for those with the expertise and resources to manage their infrastructure.
Q. What is Retrieval-Augmented Generation (RAG) and how do vector databases fit in?
A. RAG is an architecture that enhances LLMs by allowing them to retrieve relevant information from an external knowledge base before generating a response. Vector databases are central to RAG, as they efficiently store and retrieve the semantically similar data chunks that augment the LLM’s context, improving factual accuracy and reducing hallucinations.
9. Conclusion: The Future of AI is Vectorized
As we navigate through 2026, it’s abundantly clear that vector databases are no longer a niche technology but a fundamental component of the modern AI stack. From powering intelligent search engines and hyper-personalized recommendation systems to enabling sophisticated RAG architectures for LLMs, their ability to manage and query data based on semantic meaning is unlocking unprecedented possibilities for developers.
The landscape offers diverse choices, from the fully managed simplicity of Pinecone to the graph-native extensibility of Weaviate and the open-source power of Milvus. Each brings unique strengths, catering to different deployment preferences, data models, and scale requirements. The key for developers is to understand these distinctions and select the tool that best aligns with their project’s specific needs, balancing performance, scalability, ease of use, and cost.
The future of AI is undeniably vectorized. As embedding models become more sophisticated and data volumes continue to explode, the demand for efficient, scalable, and intelligent vector management will only intensify. Mastering vector databases is not just about adopting a new technology; it’s about embracing a new paradigm for building AI applications that truly understand the world around them. Get ready to vectorize your data and unlock the next generation of intelligent systems!
Thanks for reading!
We hope this deep dive into vector databases has equipped you with the knowledge to navigate the exciting world of AI development in 2026. Your insights and projects are what drive innovation!
Got feedback or questions? Drop a comment below!