

SUMMARY
Navigating AI Ethics & Responsible Development: A Developer’s Guide for 2026
Practical guidelines for developers to build ethical, fair, and transparent AI systems in 2026, addressing bias, privacy, and accountability.
Keywords: AI ethics, responsible AI, AI development, AI bias, data privacy
TABLE OF CONTENTS
1. Introduction: The Imperative for Ethical AI in 2026
2. Core Principles of Responsible AI Development
3. Addressing AI Bias: Strategies and Tools
4. Transparency and Explainability (XAI)
5. Data Privacy and Security in AI Systems
6. Accountability and Governance in AI
7. Practical Integration: Building Ethical AI into the Development Lifecycle
8. Frequently Asked Questions (FAQ)
9. Conclusion: Shaping the Future of AI Responsibly
BACKGROUND
Introduction: The Imperative for Ethical AI in 2026
The year 2026 marks a pivotal moment in the evolution of Artificial Intelligence. AI is no longer a futuristic concept; it’s deeply embedded in our daily lives, powering everything from personalized recommendations and medical diagnostics to autonomous vehicles and financial trading platforms. With this widespread integration comes immense power, and with great power, as the saying goes, comes great responsibility. The decisions made by AI systems, often operating at scales and speeds beyond human comprehension, can have profound impacts on individuals, communities, and society at large.
Recent years have seen a surge in public awareness and regulatory scrutiny regarding the ethical implications of AI. Incidents of algorithmic bias in hiring tools, privacy breaches through data exploitation, and the spread of misinformation via generative AI have underscored the urgent need for a more thoughtful and principled approach to AI development. For developers, this isn’t just about writing code that works efficiently; it’s about crafting systems that are fair, transparent, accountable, and respectful of human values.
The regulatory landscape is also rapidly maturing. The European Union’s AI Act, poised for full implementation by 2026, is setting a global benchmark for AI governance, classifying AI systems by risk level and imposing strict requirements on high-risk applications. Similar frameworks are emerging in North America and Asia, signaling a clear shift towards regulated, responsible AI. As developers, understanding and integrating ethical considerations from the ground up is no longer optional but a critical component of successful and sustainable AI innovation.
KEY POINT
By 2026, ethical AI development is not merely a best practice but a fundamental requirement, driven by both societal demands and evolving global regulatory frameworks like the EU AI Act.
CORE CONTENT
Core Principles of Responsible AI Development
Building ethical AI systems starts with a foundational understanding of key principles. These aren’t just abstract ideals; they are actionable guidelines that can be integrated into every stage of the AI development lifecycle. Kwonglish advocates for a holistic approach centered around the following core tenets:
1. Fairness and Non-Discrimination
AI systems should treat all individuals and groups equitably, avoiding outcomes that disproportionately disadvantage certain demographics based on sensitive attributes like race, gender, age, or socioeconomic status. This principle demands rigorous attention to data collection, model training, and performance evaluation across diverse population segments. For example, a credit scoring AI must not unfairly deny loans to specific ethnic groups, even if historical data shows a correlation with default rates, without a legitimate, non-discriminatory justification.
2. Transparency and Explainability (XAI)
Users and stakeholders should be able to understand how an AI system arrives at its decisions or predictions. This doesn’t necessarily mean deciphering every line of code, but rather providing interpretable insights into the factors influencing an outcome. In a medical diagnostic AI, for instance, a doctor needs to know why the system suggested a particular diagnosis, not just the diagnosis itself, to ensure patient safety and trust.
3. Accountability
There must be clear lines of responsibility for the design, deployment, and operation of AI systems. When an AI system causes harm, it should be possible to identify who is responsible and hold them accountable. This involves establishing governance structures, ethical review processes, and clear incident response plans. Companies developing AI for critical infrastructure, for example, must have robust accountability frameworks in place.
4. Privacy and Data Security
AI systems often rely on vast amounts of data, much of which can be sensitive. Developers must ensure that personal data is collected, stored, processed, and used in a secure manner, respecting user consent and adhering to strict privacy regulations like GDPR and CCPA. Techniques such as differential privacy and federated learning are becoming increasingly vital to protect user information while still enabling effective AI models.
5. Robustness and Safety
AI systems should be reliable, secure, and resilient to adversarial attacks, errors, or unexpected inputs. They must perform consistently and safely, especially in critical applications. An autonomous driving AI, for example, must be extensively tested to ensure it can handle diverse and unpredictable real-world scenarios without compromising safety.
6. Human Oversight and Control
While AI can augment human capabilities, it should not fully replace human judgment, especially in high-stakes decisions. Mechanisms for human intervention, review, and override should be built into AI systems. This principle ensures that humans remain in control, mitigating risks associated with fully autonomous decision-making in sensitive contexts.
KEY POINT
The six core principles – Fairness, Transparency, Accountability, Privacy, Robustness, and Human Oversight – form the bedrock of responsible AI development, guiding developers toward creating beneficial and trustworthy systems.
CORE CONTENT
Addressing AI Bias: Strategies and Tools
AI bias is one of the most pervasive and challenging ethical issues developers face. It occurs when an AI system produces systematically prejudiced results, often reflecting and amplifying existing societal biases present in the training data. Addressing bias is crucial for ensuring fairness and maintaining public trust.
Understanding Types of Bias
Bias can manifest in several forms throughout the AI lifecycle:
• Selection Bias: Occurs when the data used to train the model is not representative of the real-world population it will interact with. For example, if a dataset for facial recognition primarily contains images of light-skinned individuals, it may perform poorly on darker skin tones.
• Measurement Bias: Arises from systematic errors in how data is collected or labeled. An example could be inconsistent labeling of medical images across different hospitals, leading to skewed diagnostic outcomes.
• Algorithmic Bias: Can be introduced by the model architecture or training process itself, even with relatively unbiased data. This might happen if the optimization objective inadvertently favors certain groups or if regularization techniques have unintended discriminatory effects.
• Historical Bias: Reflects historical societal prejudices embedded in data, such as past hiring decisions that favored one gender over another. An AI trained on this data might perpetuate those biases.
Mitigation Strategies
Developers can employ a multi-faceted approach to mitigate bias:
Data-Centric Approaches
• Diverse Data Collection: Actively seek out and include data from underrepresented groups to ensure balanced datasets. This often involves demographic audits of training data.
• Data Augmentation: Synthetically generate data for minority groups to balance the dataset, using techniques like SMOTE (Synthetic Minority Over-sampling Technique) or generative adversarial networks (GANs).
• Pre-processing Debiasing: Apply algorithms to modify the training data before model training. This can involve re-sampling, re-weighting, or transforming features to reduce discriminatory correlations.
Model-Centric Approaches
• In-processing Debiasing: Integrate fairness constraints directly into the model training objective. This involves adding terms to the loss function that penalize discriminatory outcomes alongside prediction errors.
• Fairness-Aware Algorithms: Utilize specialized algorithms designed to promote fairness, such as those that ensure equalized odds or demographic parity across different groups.
• Post-processing Debiasing: Adjust model predictions after training to improve fairness. This could involve calibrating scores or setting different decision thresholds for various demographic groups.
Evaluation and Monitoring
• Fairness Metrics: Employ a range of quantitative metrics to assess fairness, such as statistical parity, equal opportunity, or disparate impact. Tools like IBM’s AI Fairness 360 (AIF360) provide a comprehensive suite of these metrics and debiasing algorithms.
• Continuous Monitoring: Bias is not static. Deploy robust monitoring systems to detect fairness degradation over time, as real-world data distributions can shift, introducing new biases.
Consider a hypothetical case: an AI-powered job applicant screening tool. If trained on historical hiring data where certain demographics were historically underrepresented in successful hires (e.g., 70% male, 30% female for engineering roles), the AI might learn to implicitly favor male candidates. By using AIF360, a developer could analyze the data for disparate impact, apply a pre-processing algorithm like Reweighing to balance the data, and then evaluate the model’s predictions for equal opportunity, ensuring similar true positive rates for both male and female applicants.
KEY POINT
Effective AI bias mitigation requires a holistic strategy encompassing diverse data collection, application of pre-, in-, and post-processing debiasing techniques, and continuous monitoring using established fairness metrics.
CORE CONTENT
Transparency and Explainability (XAI)
Transparency and explainability are crucial for building trust, enabling debugging, and ensuring compliance with regulations. As AI models become more complex (“black boxes”), understanding their decision-making processes becomes increasingly challenging yet vital.
Why XAI Matters
• Trust and Acceptance: Users are more likely to trust and adopt AI systems if they understand how they work and why specific decisions are made.
• Debugging and Improvement: Explanations help developers identify flaws, biases, or unexpected behaviors in models, facilitating debugging and performance improvement.
• Compliance: Regulations like GDPR’s “right to explanation” and the EU AI Act’s transparency requirements mandate some level of explainability for high-risk AI systems.
• Ethical Review: XAI provides insights necessary for ethical auditors to assess fairness, accountability, and potential societal impacts.
• Legal Recourse: In cases where AI decisions lead to adverse outcomes, explanations are vital for legal challenges and demonstrating compliance or liability.
Key XAI Techniques for Developers
XAI methods can be broadly categorized into intrinsic (interpretable models) and post-hoc (explaining black-box models). Here are some common and effective post-hoc techniques:
LIME (Local Interpretable Model-agnostic Explanations)
LIME explains individual predictions of any black-box classifier by approximating it locally with an interpretable model (e.g., linear model). It perturbs the input, observes the black-box model’s predictions on these perturbed samples, and then trains a simple, interpretable model on this new dataset, weighted by proximity to the original instance. This highlights which features are most important for that specific prediction.
SHAP (SHapley Additive exPlanations)
SHAP values attribute the prediction of a model to each feature. Based on game theory, SHAP calculates the average marginal contribution of a feature value across all possible coalitions of features. This provides a consistent and locally accurate method for explaining individual predictions and can also be aggregated to understand global model behavior.
Feature Importance
While simpler, techniques like permutation feature importance (for models like Random Forests or Gradient Boosting) or examining coefficients in linear models can provide a global understanding of which features are generally most influential across the dataset. For deep learning models, attention mechanisms can highlight important parts of the input, such as words in a sentence or regions in an image.
Balancing interpretability with performance is often a trade-off. Highly accurate models like deep neural networks are often less interpretable, while simple models like decision trees are highly interpretable but may sacrifice accuracy. Developers must choose XAI methods appropriate for the model complexity and the context of its deployment. For high-stakes applications, a more robust explanation is almost always preferred, even if it adds computational overhead.
KEY POINT
XAI is fundamental for trust, debugging, and compliance; developers should leverage techniques like LIME and SHAP to provide granular explanations for individual predictions, balancing model performance with the need for interpretability.
CORE CONTENT
Data Privacy and Security in AI Systems
The hunger for data is inherent to modern AI, but this appetite must be tempered by stringent privacy and security practices. In 2026, with data breaches becoming more sophisticated and privacy regulations tightening globally, protecting user data in AI systems is paramount.
The Evolving Regulatory Landscape
Beyond GDPR (Europe) and CCPA/CPRA (California), several new data privacy regulations are expected to be in full effect or under consideration globally by 2026. These regulations often include specific clauses for AI, such as requirements for data minimization, purpose limitation, and the right to opt-out of automated decision-making. Non-compliance can lead to hefty fines, reputational damage, and loss of user trust. For instance, a violation of GDPR can result in fines up to €20 million or 4% of annual global turnover, whichever is higher.
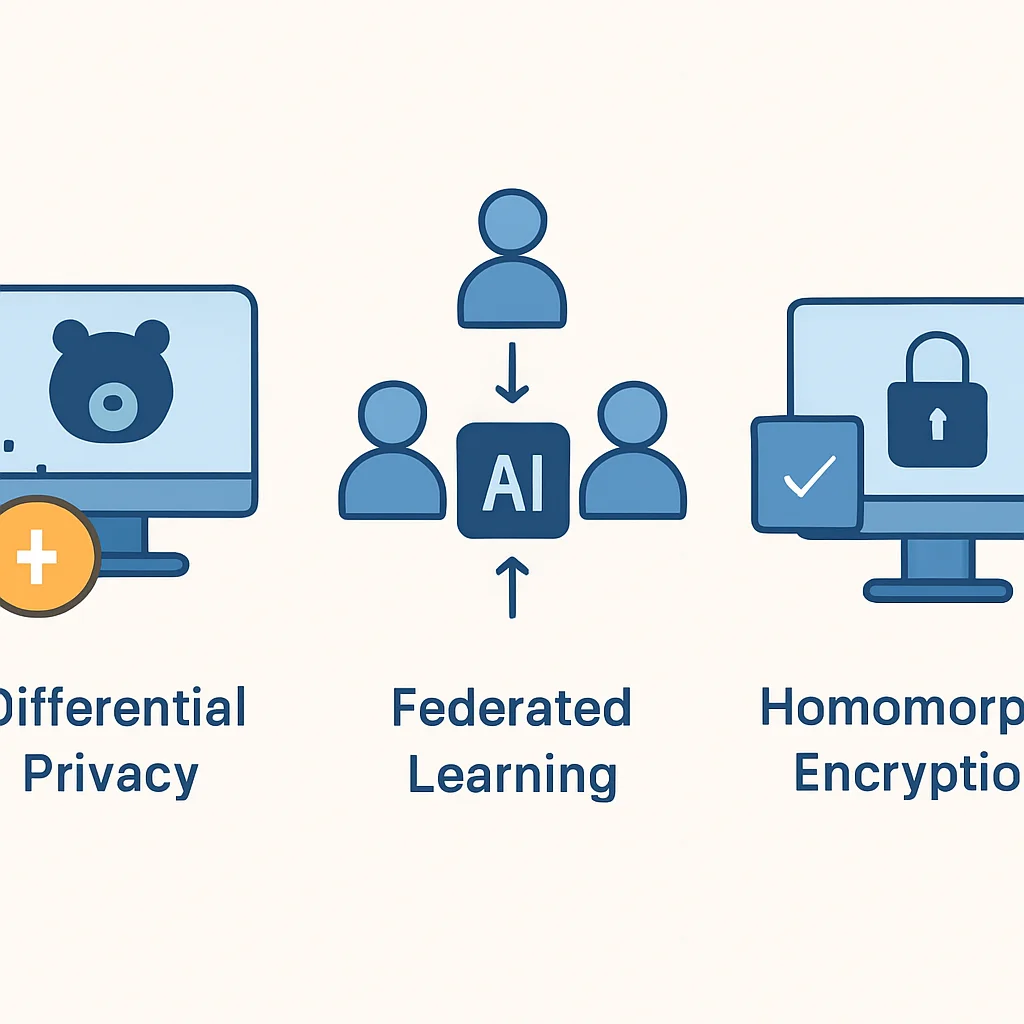
Key Privacy-Enhancing Technologies (PETs)
Developers can leverage several cutting-edge techniques to build privacy-preserving AI:
Differential Privacy
This technique adds carefully calibrated noise to datasets or query results to obscure individual data points while still allowing for accurate aggregate analysis. It provides a strong, mathematically provable guarantee that an individual’s presence or absence in a dataset does not significantly alter the outcome of an analysis. Major tech companies like Google and Apple use differential privacy to collect aggregate user data for product improvement without compromising individual privacy.
Federated Learning
Instead of centralizing data, federated learning trains AI models on decentralized datasets located on individual devices (e.g., smartphones, IoT devices). Only the model updates (gradients) are sent to a central server, not the raw data. This keeps sensitive user data on the user’s device, significantly enhancing privacy, especially for mobile keyboard prediction or health monitoring applications.
Homomorphic Encryption
This advanced cryptographic technique allows computations to be performed on encrypted data without decrypting it first. The results of these computations remain encrypted and, when decrypted, are the same as if the operations had been performed on the unencrypted data. While computationally intensive, homomorphic encryption offers the highest level of data privacy for sensitive AI tasks, such as processing medical records in the cloud.
Beyond these technical solutions, developers must also adopt robust data governance practices:
• Data Minimization: Collect only the data absolutely necessary for the AI’s purpose.
• Purpose Limitation: Use data only for the specific purposes for which it was collected and consented to.
• Secure Storage and Access: Implement strong encryption, access controls, and regular security audits for all data storage and processing infrastructure.
• Anonymization/Pseudonymization: Where possible, remove or obscure direct identifiers from data. While not a complete solution, it reduces re-identification risks.
KEY POINT
Robust data privacy in AI for 2026 demands adherence to evolving regulations and the strategic implementation of PETs like differential privacy and federated learning, alongside strict data governance.
CORE CONTENT
Accountability and Governance in AI
Establishing clear lines of accountability and robust governance structures is fundamental to responsible AI development. As AI systems grow in complexity and autonomy, determining who is responsible when things go wrong becomes critical. In 2026, the absence of clear accountability frameworks will expose organizations to significant legal, financial, and reputational risks.
The Growing Regulatory Landscape for AI Governance
The EU AI Act, a landmark regulation, categorizes AI systems by risk level: unacceptable risk, high risk, limited risk, and minimal risk. High-risk AI systems (e.g., in critical infrastructure, employment, law enforcement) face stringent requirements, including risk management systems, data governance, technical documentation, human oversight, robustness, accuracy, and post-market monitoring. Similar initiatives are underway in other jurisdictions, pushing for mandatory impact assessments and clear audit trails for AI decisions. Developers must embed these requirements into their development processes from the outset.
Key Pillars of AI Governance
Effective AI governance involves a combination of organizational processes, documentation, and continuous oversight:
Ethical AI Review Boards
Many organizations are establishing dedicated committees, often multidisciplinary, to review AI projects for ethical risks, potential biases, and alignment with corporate values and regulatory requirements. These boards can provide guidance, approve deployments, and oversee impact assessments, acting as a critical human oversight layer.
AI Impact Assessments (AIIA)
Similar to Data Protection Impact Assessments (DPIAs), AIIAs systematically identify, evaluate, and mitigate potential risks and societal impacts of an AI system before its deployment. This involves assessing risks related to fairness, privacy, autonomy, and safety, and outlining mitigation strategies. For high-risk AI, these assessments are becoming mandatory.
Robust Documentation and Audit Trails
Comprehensive documentation is essential for accountability. This includes detailed records of data sources, model architectures, training procedures, fairness metrics, design choices, and human oversight interventions. Audit trails of AI decisions, especially for high-risk applications, enable post-hoc analysis and accountability if issues arise.
Continuous Monitoring and Incident Response
AI systems in production require continuous monitoring for performance drift, emerging biases, and security vulnerabilities. Organizations need clear protocols for identifying, responding to, and remediating ethical or technical failures, ensuring that accountability is maintained even after deployment.
For developers, this translates into a need to understand the broader context of their AI applications, actively participate in impact assessments, and ensure their code and data practices are thoroughly documented and auditable. Integrating governance practices early in the development cycle, rather than as an afterthought, is key to building responsible AI solutions.
KEY POINT
Robust AI governance, driven by regulations like the EU AI Act, necessitates ethical review boards, mandatory impact assessments, comprehensive documentation, and continuous monitoring to ensure accountability and mitigate risks.

PROBLEM SOLVING
Technical Challenges and Solutions in Ethical AI
Implementing ethical AI principles often introduces technical hurdles. Developers frequently encounter trade-offs and complexities that require thoughtful solutions. Here, we explore some common challenges and their practical resolutions.
Quantifying and Measuring Fairness
Fairness is a multifaceted concept with no single, universally accepted definition. Different fairness metrics (e.g., demographic parity, equal opportunity, equal accuracy) can conflict, and optimizing for one might degrade another. Deciding which metric is appropriate for a given application is a significant challenge, especially when legal or societal definitions of fairness are ambiguous.
SOLUTION — Contextual Fairness Definitions and Multi-Objective Optimization
Developers should work closely with domain experts, legal teams, and ethicists to define fairness contextually for each specific AI application. Instead of aiming for a single metric, adopt a multi-objective optimization approach, treating fairness metrics as additional objectives alongside traditional performance metrics (e.g., accuracy, precision). Tools like IBM’s AI Fairness 360 (AIF360) provide a framework to explore and mitigate biases across various fairness definitions. Furthermore, visualizing trade-offs between different fairness metrics and model performance can help stakeholders make informed decisions.
CODE EXPLANATION
This Python code snippet demonstrates how to use the AIF360 library to calculate disparate impact, a common fairness metric, for a hypothetical model’s predictions. It shows how to define protected attributes and measure the ratio of favorable outcomes for unprivileged versus privileged groups.
import pandas as pd
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import BinaryLabelDatasetMetric
# Hypothetical data
data = {'age': [25, 30, 35, 40, 45, 50, 55, 60],
'gender': ['Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female'],
'credit_score': [700, 650, 720, 680, 710, 660, 730, 690],
'loan_approved': [1, 0, 1, 1, 1, 0, 1, 1]} # 1 for approved, 0 for denied
df = pd.DataFrame(data)
# Define protected attribute and its privileged/unprivileged values
protected_attribute_names = ['gender']
privileged_classes = [['Male']] # Male is privileged group
unprivileged_classes = [['Female']] # Female is unprivileged group
# Create AIF360 dataset
bld = BinaryLabelDataset(
df=df,
label_names=['loan_approved'],
protected_attribute_names=protected_attribute_names,
privileged_protected_attributes=privileged_classes,
unprivileged_protected_attributes=unprivileged_classes
)
# Calculate metrics for the dataset
metric_original_dataset = BinaryLabelDatasetMetric(bld,
unprivileged_groups=bld.unprivileged_protected_attributes,
privileged_groups=bld.privileged_protected_attributes)
# Disparate Impact: Ratio of (rate of favorable outcome for unprivileged group) to (rate of favorable outcome for privileged group)
# A value of 1 implies no disparate impact. Values below 0.8 or above 1.25 are often considered problematic.
disparate_impact = metric_original_dataset.disparate_impact()
print(f"Disparate Impact (loan approval for Female vs Male): {disparate_impact:.2f}")
# Example: If male approval rate is 80% and female approval rate is 40%, DI = 0.5, indicating bias.
# In this dummy data:
# Male approvals: 3/4 = 0.75
# Female approvals: 2/4 = 0.5
# Disparate Impact = 0.5 / 0.75 = 0.67
Balancing Performance and Explainability
There’s often a perceived trade-off between model accuracy and interpretability. Highly complex models like deep neural networks achieve superior performance in many tasks but are notoriously difficult to explain (black-box models). Conversely, simpler, more interpretable models (e.g., linear regression, decision trees) might not capture the nuances of complex data, leading to lower predictive accuracy. Developers struggle to satisfy both demands simultaneously.
SOLUTION — Post-Hoc Explainability and Hybrid Models
Instead of sacrificing performance, leverage post-hoc explainability techniques such as LIME and SHAP. These methods can provide local explanations for individual predictions of complex black-box models without altering their underlying architecture. For global interpretability, consider model distillation, where a complex “teacher” model trains a simpler, more interpretable “student” model. Another approach is to use hybrid models, where a black-box model handles complex feature extraction, and an interpretable model makes the final decision based on these features, or to use selective explainability, focusing on explaining only high-risk or critical decisions.
CODE EXPLANATION
This snippet illustrates how to use the SHAP library to explain a single prediction from a scikit-learn random forest classifier. SHAP values indicate how much each feature contributes to pushing the model’s output from the base value (average prediction) to the current prediction.
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# Generate synthetic data
X, y = make_classification(n_samples=100, n_features=4, n_informative=2,
n_redundant=0, random_state=42)
feature_names = ['feature_A', 'feature_B', 'feature_C', 'feature_D']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# Train a RandomForestClassifier (black-box model)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Create a SHAP explainer
explainer = shap.TreeExplainer(model)
# Select an instance to explain (e.g., the first test instance)
instance_to_explain = X_test[0]
# Calculate SHAP values for the instance
shap_values = explainer.shap_values(instance_to_explain)
# For binary classification, shap_values will be a list of two arrays (one for each class)
# Let's explain the prediction for class 1 (positive outcome)
shap_values_class_1 = shap_values[1]
print(f"Explaining prediction for instance: {instance_to_explain}")
print(f"Model prediction (class 1 probability): {model.predict_proba(instance_to_explain.reshape(1, -1))[0, 1]:.2f}")
print("\nSHAP values for each feature (contribution to class 1 prediction):")
for i, feature in enumerate(feature_names):
print(f" {feature}: {shap_values_class_1[i]:.4f}")
# A positive SHAP value for a feature means it increases the probability of class 1.
# A negative SHAP value means it decreases it.
Data Scarcity for Debiasing
Often, the very groups that are most susceptible to AI bias are also underrepresented in available datasets. This creates a vicious cycle: limited data for minority groups makes it harder to detect and mitigate bias, leading to models that perform poorly or unfairly for these groups. Acquiring sufficient, diverse, and high-quality data for robust debiasing can be costly, time-consuming, and ethically complex itself.
SOLUTION — Synthetic Data Generation and Transfer Learning
To address data scarcity, developers can employ synthetic data generation techniques using privacy-preserving generative models (e.g., GANs, VAEs) to create realistic, yet artificial, data points for underrepresented groups. This can augment existing datasets without exposing real sensitive information. Another powerful approach is transfer learning: pre-train a model on a large, general dataset (even if it has some biases), and then fine-tune it on a smaller, more balanced, and domain-specific dataset. This allows the model to leverage general knowledge while adapting to the specific context and reducing reliance on large quantities of sensitive data. Active learning can also be used to strategically acquire more data points for regions where the model exhibits high uncertainty or potential bias.
CODE EXPLANATION
This Python code demonstrates a conceptual example of synthetic data generation for a minority class using the SMOTE (Synthetic Minority Over-sampling Technique) algorithm. SMOTE creates new synthetic examples that are similar to existing minority class examples, effectively balancing the dataset for training.
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
import pandas as pd
import numpy as np
# Generate a highly imbalanced dataset
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1, weights=[0.95, 0.05],
flip_y=0, random_state=42)
print(f"Original dataset shape: X={X.shape}, y={y.shape}")
unique, counts = np.unique(y, return_counts=True)
print(f"Original class distribution: {dict(zip(unique, counts))}")
# Apply SMOTE to oversample the minority class (class 1)
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
print(f"\nResampled dataset shape: X={X_resampled.shape}, y={y_resampled.shape}")
unique_resampled, counts_resampled = np.unique(y_resampled, return_counts=True)
print(f"Resampled class distribution: {dict(zip(unique_resampled, counts_resampled))}")
# Now X_resampled and y_resampled have a more balanced distribution,
# which can be used to train a fairer model.
PRACTICAL APPLICATION
Practical Integration: Building Ethical AI into the Development Lifecycle
Integrating ethical considerations isn’t a one-time task; it’s an ongoing process that should be woven into every stage of the AI development lifecycle. Here’s a practical, step-by-step guide for developers in 2026:
1. Pre-Development: Ethical AI Assessment & Requirements
Before writing any code, conduct an initial ethical impact assessment. Identify potential risks related to bias, privacy, and societal impact. Define clear ethical requirements alongside functional and non-functional ones. Consult with stakeholders, legal experts, and ethical review boards. Document the intended purpose, scope, and potential beneficiaries and harms of the AI system.
2. Data Collection & Preparation: Bias Detection and Mitigation
Actively audit data sources for representativeness and potential biases. Implement data minimization principles. Use privacy-enhancing technologies (PETs) like differential privacy during collection. During preparation, use tools like AIF360 to detect statistical biases across protected attributes. Apply pre-processing debiasing techniques (e.g., reweighing, synthetic data generation) to create a fairer training dataset. Document data provenance and any transformations applied.
3. Model Design & Training: Fairness and Explainability Integration
Incorporate fairness-aware algorithms or add fairness constraints to the model’s objective function. Prioritize robust model architectures that are less susceptible to adversarial attacks. Integrate explainability from the outset, choosing models that are inherently interpretable or designing for post-hoc XAI. During training, monitor fairness metrics alongside accuracy. Experiment with various debiasing techniques and evaluate their impact on both performance and fairness for different groups.
4. Deployment & Monitoring: Continuous Ethical Oversight
Before deployment, conduct a final, comprehensive ethical review and validate the model’s fairness and robustness on unseen data. After deployment, establish continuous monitoring systems to detect performance drift, concept drift, and emerging biases in real-time. Implement mechanisms for human oversight and intervention. Ensure clear incident response plans are in place for ethical failures. Regularly re-evaluate the model’s impact and update as necessary.
5. Documentation & Communication: Transparency and Accountability
Create detailed “model cards” or “datasheets for datasets” that document the model’s purpose, performance metrics (including fairness metrics for various groups), limitations, and intended use cases. Clearly communicate the AI’s capabilities and limitations to end-users. Maintain a transparent audit trail of all development decisions, ethical reviews, and changes. Foster an open dialogue with users and stakeholders to gather feedback and address concerns.
KEY POINT
Integrating ethical AI is an end-to-end process, from initial assessment and data preparation to model deployment and continuous monitoring, requiring meticulous documentation and transparent communication at every stage.
Frequently Asked Questions (FAQ)
Q. Why is AI ethics particularly critical for developers in 2026?
In 2026, AI is deeply integrated into critical societal functions, making its impact on individuals and communities profound. Furthermore, new regulations like the EU AI Act are imposing strict legal requirements for ethical development, making it a compliance necessity, not just a best practice.
Q. How can I measure fairness in my AI model when there are so many metrics?
There isn’t a single “correct” fairness metric. You should define fairness contextually with stakeholders, considering the potential harms. Tools like IBM’s AI Fairness 360 (AIF360) allow you to analyze multiple metrics (e.g., disparate impact, equal opportunity) and understand the trade-offs, helping you choose the most appropriate one for your specific application.
Q. What are the best ways to ensure data privacy in AI development for 2026?
Prioritize data minimization and purpose limitation. Leverage Privacy-Enhancing Technologies (PETs) like differential privacy for adding noise to data, federated learning for decentralized training, and homomorphic encryption for secure computation on encrypted data. Always obtain informed consent and adhere to global privacy regulations.
Q. Is it possible to have both high performance and high explainability in AI models?
While often a trade-off, it’s increasingly possible to achieve both. For complex models, post-hoc explainability methods like LIME and SHAP can provide local explanations without sacrificing performance. Techniques like model distillation or using hybrid models can also offer a balance by combining the strengths of complex and interpretable architectures.
Q. What role does human oversight play in responsible AI?
Human oversight ensures that AI systems augment rather than replace human judgment, especially in high-stakes situations. It involves designing systems with clear human intervention points, ethical review processes, and the ability for humans to override AI decisions. This maintains human accountability and prevents fully autonomous decisions with potentially adverse consequences.
WRAP-UP
Conclusion: Shaping the Future of AI Responsibly
As we navigate 2026, the landscape of AI development is undeniably shaped by ethical considerations. The rapid advancements in machine learning, coupled with increasing societal reliance on AI, demand that developers move beyond mere technical proficiency to embrace a holistic, values-driven approach. Building responsible AI is not just about avoiding harm; it’s about actively creating systems that foster fairness, respect privacy, promote transparency, and uphold human dignity.
The tools and strategies discussed—from bias mitigation techniques and explainable AI frameworks to privacy-enhancing technologies and robust governance structures—provide a clear roadmap. However, these are merely instruments; their effectiveness ultimately depends on the commitment and ethical mindset of the developers wielding them. The future of AI, a future brimming with potential, rests in the hands of those who build it. By integrating ethical principles into every line of code and every design decision, developers can ensure that AI serves humanity’s best interests, unlocking innovation that is both powerful and profoundly beneficial.
The journey towards truly responsible AI is continuous, requiring ongoing learning, adaptation, and collaboration across disciplines. As the technical capabilities of AI evolve, so too must our ethical frameworks and the practical application of those principles. Let’s collectively commit to building an AI future that is not only intelligent but also just, equitable, and trustworthy.
KEY POINT
Responsible AI development in 2026 hinges on developers’ commitment to integrating ethical principles throughout the entire lifecycle, ensuring AI systems are not only technically advanced but also socially beneficial and trustworthy.
Thanks for reading!
We hope this guide provides valuable insights for navigating the complex yet crucial landscape of AI ethics and responsible development in 2026. Your contributions are vital to shaping a positive AI future.
Got feedback or questions? Drop a comment below! We’d love to hear your thoughts and experiences.